
Abstrak
Penanaman kata yang berasal dari korpus bahasa yang besar telah berhasil digunakan dalam ilmu kognitif dan kecerdasan buatan untuk merepresentasikan makna linguistik. Akan tetapi, masih ada perdebatan mengenai seberapa baik mereka mengodekan informasi yang berguna tentang kualitas persepsi suatu konsep. Perdebatan ini penting untuk mengidentifikasi cakupan perwujudan dalam semantik manusia. Jika properti objek persepsi dapat disimpulkan dari penanaman kata yang berasal dari bahasa saja, ini menunjukkan bahwa bahasa menyediakan tambahan yang berguna untuk pengalaman persepsi langsung guna memperoleh pengetahuan konseptual semacam ini. Penelitian sebelumnya telah menunjukkan kinerja yang beragam ketika penanaman digunakan untuk memprediksi kualitas persepsi. Di sini, kami menguji apakah kami dapat meningkatkan kinerja dengan memanfaatkan kemampuan model bahasa berbasis Transformer untuk merepresentasikan makna kata dalam konteks. Untuk tujuan ini, kami melakukan dua eksperimen. Eksperimen pertama kami menyelidiki representasi kata benda. Kami menghasilkan penanaman Word2Vec dan BERT yang didekontekstualisasikan (“arang”) dan dikontekstualisasikan (“kecerahan arang”) untuk sekumpulan besar konsep dan membandingkan kemampuan mereka untuk memprediksi penilaian manusia terhadap kecerahan konsep. Kami mengulangi prosedur ini untuk juga menyelidiki bentuk konsep-konsep tersebut. Secara umum, kami menemukan kinerja prediksi yang sangat baik untuk bentuk, dan kinerja yang lebih sederhana untuk kecerahan. Penambahan konteks tidak meningkatkan kinerja prediksi persepsi. Dalam Eksperimen 2, kami menyelidiki representasi frasa kata sifat-kata benda. Kinerja prediksi persepsi secara umum ditemukan baik, dengan sifat kecerahan kata sifat yang tidak aditif tercermin dalam penyematan kata. Kami juga menemukan bahwa penambahan konteks memiliki dampak terbatas pada seberapa baik fitur persepsi dapat diprediksi. Kami membingkai hasil ini terhadap pekerjaan terkini tentang interpretabilitas model bahasa dan perdebatan seputar perwujudan dalam pemrosesan konseptual manusia.
1 Pendahuluan
Pemahaman kita tentang dunia dibentuk oleh informasi persepsi yang kita serap melalui pengalaman kita (Gibbs Jr, 2005 ; Rogers & Wolmetz, 2016 ). Informasi persepsi ini dapat menjadi penting secara konseptual—misalnya, kita tahu bahwa cokelat hitam rasanya lebih pahit daripada cokelat putih. Sejauh mana informasi persepsi tersebut membentuk representasi semantik telah menjadi perdebatan inti dalam ilmu kognitif (Barsalou, 2008 ; Louwerse, 2011 ; Pylyshyn, 1980 ; Rogers & McClelland, 2004 ). Satu pertanyaan kunci yang muncul dari ini menyangkut seberapa banyak informasi pengalaman yang dapat dipelajari dari konten linguistik saja (Dove, 2014 ). Model komputasi yang dilatih pada korpora bahasa yang besar memberikan perspektif penting tentang perdebatan ini. Model-model ini tampaknya memperoleh representasi semantik yang canggih dari masukan linguistik saja, tanpa akses ke pengalaman persepsi. Model bahasa biasanya menghasilkan representasi berdimensi tinggi untuk kata dan frasa yang disebut “embeddings,” yang menempatkan konsep dalam ruang semantik. Namun, kritik inti dari word embeddings ini adalah bahwa dimensinya sulit untuk ditafsirkan dan sejauh mana mereka secara setia mewakili aspek persepsi semantik (seperti warna cokelat) masih belum pasti (Chersoni, Santus, Huang, & Lenci, 2021 ; Ettinger, 2020 ). Salah satu cara untuk mengatasi masalah ini adalah dengan membandingkan word embeddings dengan penilaian manusia atau data neuroimaging untuk memeriksa sejauh mana mereka meniru semantik manusia (Abnar, Ahmed, Mijnheer, & Zuidema, 2018 ; Ettinger, 2020 ; Hollenstein, de la Torre, Langer, & Zhang, 2019 ; Turton, Vinson, & Smith, 2020, 2021 ; Utsumi, 2020 ). Dalam konteks ini, penelitian ini bertujuan untuk menguji seberapa baik penyematan yang diperoleh dari model memprediksi penilaian manusia terhadap keunggulan sifat persepsi tertentu dari objek, dan apakah konteks linguistik tambahan meningkatkan prediksi ini. Dengan demikian, kami berharap dapat memberikan wawasan baru tentang sejauh mana pengetahuan persepsi dapat diperoleh dari bahasa saja.
1.1 Pemrosesan konseptual: Teori dan kerangka kerja
Secara historis, dua perspektif teoritis yang berlawanan tentang hakikat representasi semantik telah dipertentangkan. Penjelasan simbolis tentang kognisi mengklaim bahwa makna diekstraksi dari bahasa dan diabstraksikan menjadi representasi amodal (Pylyshyn, 1980 ). Sebaliknya, penjelasan kognisi yang diwujudkan mengusulkan bahwa kognisi manusia (dan dengan perluasan, bahasa) pada dasarnya didasarkan pada pengalaman dan sistem sensorimotor (Bolognesi & Steen, 2018 ; Gibbs Jr, 2005 ). Di antara kedua ekstrem ini, sejumlah perspektif hibrida membayangkan peran untuk representasi yang berasal dari bahasa dan landasan persepsi dalam mendukung pemrosesan semantik (Andrews, Frank, & Vigliocco, 2014 ; Barsalou, Santos, Simmons, & Wilson, 2008 ; Louwerse, 2018 ). Di antara catatan-catatan ini, hakikat representasi itu sendiri, serta sejauh mana informasi perseptual penting bagi pembentukan representasi ini, masih diperdebatkan (Kiefer & Pulvermüller, 2012 ). Perspektif simbolik dan yang diwujudkan telah didukung oleh sejumlah besar penelitian yang sering kali mengikuti garis metodologis yang berbeda, dengan banyak bukti untuk kognisi simbolik berasal dari model komputasional, sementara bukti untuk kognisi yang diwujudkan dapat ditemukan dalam penelitian dengan eksperimen manusia (Andrews et al., 2014 ; Louwerse, 2018 ).
Sekarang ada bukti luas dari eksperimen perilaku dan neuroimaging yang mendukung gagasan bahwa representasi perseptual sering diaktifkan selama pemahaman bahasa (Hauk, 2016 ; Kiefer & Pulvermüller, 2012 ; Louwerse, 2018 ; Meteyard, Cuadrado, Bahrami, & Vigliocco, 2012 ). Misalnya, latensi respons dari tugas verifikasi gambar telah menunjukkan bahwa pemahaman peka terhadap orientasi objek dalam gambar, serta bentuk objek (Stanfield & Zwaan, 2001 ; Zwaan, Stanfield, & Yaxley, 2002 ). Di sini, latensi respons lebih pendek untuk gambar objek yang cocok dalam orientasi atau bentuk dengan yang disarankan oleh konteks sebelumnya, daripada untuk gambar objek yang tidak cocok. Sementara itu, bukti dari neuroimaging telah memberikan wawasan tambahan ke dalam antara informasi semantik dan persepsi. Misalnya, Simmons dan rekan-rekannya ( 2007 ) menunjukkan bahwa wilayah korteks yang sangat terkait dengan persepsi warna juga aktif saat memproses istilah warna yang disajikan sebagai properti objek (misalnya, “RUMPUT-hijau”). Hasil neuroimaging serupa juga diperoleh untuk modalitas persepsi lainnya, seperti tindakan (Hauk, Johnsrude, & Pulvermüller, 2004 ).
Namun, banyak penelitian ini secara tradisional memperlakukan representasi konseptual sebagai sesuatu yang statis dan bebas konteks, tanpa membahas fleksibilitas yang terjadi ketika konsep digunakan dalam konteks yang berbeda (Hoffman, Lambon Ralph, & Rogers, 2013 ; Yee & Thompson-Schill, 2016 ). Banyak kata memiliki konotasi yang sangat berbeda dalam situasi yang berbeda. Kata “bank” harus membangkitkan persepsi bangunan besar ketika digunakan dalam konteks jalan kota, tetapi lereng berumput ketika digunakan dalam konteks sungai. Tugas juga memengaruhi perwujudan: kata-kata yang sama dapat melibatkan sistem visual atau sistem motorik, tergantung pada properti mana yang relevan dengan tugas peserta saat ini (van Dam, van Dijk, Bekkering, & Rueschemeyer, 2012 ). Temuan seperti ini menunjukkan bahwa orang secara fleksibel membentuk kembali representasi semantik mereka saat mereka menghadapi situasi yang berbeda (Barsalou, 1983 ; Jamieson, Johns, Vokey, & Jones, 2022 ). Mereka juga menyarankan bahwa tingkat pengaktifan informasi persepsi bergantung pada tugas yang kita lakukan dan konteks di mana kata itu disajikan (Barsalou et al., 2008 ).
Untuk memahami sejauh mana informasi persepsi tertanam dalam bahasa, banyak peneliti telah menyelidiki kemampuan model bahasa komputasional yang semata-mata terekspos pada masukan bahasa. Kami mengulas temuan-temuan ini di bagian berikutnya. Untuk saat ini, penting untuk menyoroti bahwa banyak dari penelitian ini juga telah dilakukan dari perspektif bebas konteks. Model-model pionir seperti analisis semantik laten (LSA; Landauer & Dumais, 1997 ), serta model-model yang lebih baru seperti word2vec (Mikolov, Chen, Corrado, & Dean, 2013 ; Mikolov, Sutskever, Chen, Corrado, & Dean, 2013 ) dan GloVe (Pennington, Socher, & Manning, 2014 ) sangat berharga dalam menemukan struktur semantik yang ada dalam bahasa. Tetapi model-model ini merepresentasikan setiap kata sebagai penanaman statis yang independen konteks. Mengingat pentingnya konteks dalam membentuk representasi semantik manusia, representasi bebas konteks ini kemungkinan meremehkan informasi semantik yang ada dalam bahasa. Perkembangan yang lebih baru dalam pemrosesan bahasa alami, dalam bentuk model berbasis Transformer, memungkinkan penyematan kata kontekstual untuk dibuat (Devlin, Chang, Lee, & Toutanova, 2018 ; Misra, Ettinger, & Rayz, 2020 ; Ontanon, Ainslie, Fisher, & Cvicek, 2022 ). Penyematan ini memberikan representasi kontekstual dari sebuah kata, sehingga penyematan untuk kata polisemi, seperti “bank,” akan berbeda di seluruh kalimat yang menggunakan arti kata yang berbeda. Dalam studi ini, kami menyelidiki jenis informasi persepsi yang ada dalam berbagai bentuk penyematan kontekstual.
1.2 Menafsirkan isi semantik dari penyematan kata
Penanaman kata, sebagai representasi bahasa berbasis vektor, sangat terkait dengan hipotesis distribusional. Ini adalah gagasan bahwa kesamaan semantik antara dua ekspresi linguistik dapat dipahami sebagai fungsi dari kesamaan konteks linguistik tempat mereka muncul (Firth, 1957 ; Harris, 1954 ; Lenci, 2008 ). Ini telah banyak memengaruhi ilmu kognitif semantik, di mana hipotesis distribusional juga diajukan sebagai hipotesis kognitif untuk organisasi makna. Dengan demikian, model yang berasal dari data bahasa distribusional telah digunakan untuk memodelkan beberapa aspek pemrosesan bahasa manusia, seperti asosiasi kata, defisit semantik, dan kategorisasi (Bullinaria & Levy, 2007 ; Griffiths, Steyvers, & Tenenbaum, 2007 ; Vigliocco, Vinson, Lewis, & Garrett, 2004 ). Contoh awal model distribusional ini mencakup LSA dan model Topik (Griffiths et al., 2007 ; Landauer & Dumais, 1997 ), sementara contoh yang lebih baru mencakup Word2Vec dan GloVe (Mikolov et al., 2013 ; Mikolov et al., 2013 ; Pennington et al., 2014 ).
Penanaman kata yang diekstrak dari model-model ini dapat direpresentasikan secara geometris dalam ruang semantik, di mana kata-kata yang lebih terkait secara semantik mengelompok bersama (Riordan & Jones, 2011 ). Karena itu, kesamaan semantik umumnya digunakan sebagai metrik evaluasi untuk representasi distribusional (Günther, Dudschig, & Kaup, 2016 ; Jones, Kintsch, & Mewhort, 2006 ; Lenci, 2008 ; Lowe & McDonald, 2000 ). Misalnya, Grand dan rekannya menggunakan proyeksi semantik untuk membandingkan representasi internal penanaman kata terhadap penilaian manusia terhadap kategori dan properti objek. Penulis membangun skala yang menunjukkan fitur semantik yang menarik, katakanlah ukuran, dan mampu membandingkan representasi internal penanaman kata dengan membuat subruang fitur di mana ukuran memengaruhi pola kesamaan antara penanaman. Mereka menemukan bahwa kesamaan berdasarkan fitur ini memprediksi penilaian fitur manusia, dan menyimpulkan bahwa representasi geometris dari penempatan kata mengandung pengetahuan konseptual yang kaya (Grand, Blank, Pereira, & Fedorenko, 2022 ).
Pendekatan lain berfokus pada pembelajaran pemetaan antara penempatan kata dan norma properti sebagai cara untuk mendasarkannya pada representasi yang dapat ditafsirkan (Chersoni et al., 2021 ; Derby, Miller, & Devereux, 2019 ; Fǎgǎrǎşan, Vecchi, & Clark, 2015 ; Utsumi, 2020 ). Penelitian sebelumnya yang menggunakan pendekatan ini telah menghasilkan temuan beragam tentang sejauh mana penempatan kata meniru aspek persepsi semantik manusia. Abdou dan rekan-rekannya ( 2021 ) mengeksplorasi penempatan BERT, RoBERTa, dan ELECTRA untuk kata-kata berwarna (misalnya, “kuning”) menggunakan analisis kesamaan representasional (RSA) dan regresi linier. Mereka menemukan bahwa penempatan kata-kata berwarna selaras dengan struktur ruang warna 3D, CIELAB, menyimpulkan bahwa perkiraan ruang warna persepsi dapat diekstraksi dari teks saja. Namun, keberhasilan dalam mengekstraksi pengetahuan warna dari embedding belum direplikasi saat menyelidiki informasi warna tentang objek (misalnya, pisang berwarna kuning). Sommerauer dan Fokkens ( 2018 ) menggunakan embedding Word2Vec untuk mengklasifikasikan objek menurut apakah objek tersebut memiliki fitur tertentu (misalnya, berwarna kuning, berbahaya). Sementara fitur fungsional dan relevan dengan perilaku umumnya diklasifikasikan dengan baik, kinerjanya buruk untuk fitur persepsi, termasuk warna. Dalam nada yang sama, Lucy dan Gauthier ( 2017 ) mengevaluasi word embedding pada seberapa baik mereka memprediksi fitur persepsi dan konseptual dari konsep konkret, menggunakan kumpulan data norma semantik yang dikumpulkan dari manusia sebagai standar emas. Mereka menguji berbagai jenis penempatan kata (GloVe dan Word2Vec) menggunakan kumpulan data norma semantik McRae dan CSLB (Devereux, Tyler, Geertzen, & Randall, 2014 ; McRae, Cree, Seidenberg, & McNorgan, 2005 ) dan menemukan bahwa penempatan tersebut gagal mengodekan banyak fitur persepsi menonjol dari konsep tersebut, dibandingkan dengan kategori nonpersepsi yang ketat (seperti fitur taksonomi dan fungsional).
Studi yang disebutkan sebelumnya menggunakan embeddings untuk memprediksi ada atau tidaknya fitur biner (misalnya, berwarna kuning vs. tidak berwarna kuning). Sementara itu, studi lain telah mencoba memprediksi peringkat berkelanjutan dari pentingnya atau relevansi berbagai jenis informasi. Misalnya, Chersoni dan rekan-rekannya ( 2021 ) melatih jaringan saraf untuk mempelajari pemetaan dari word embeddings (kedua model berbasis hitungan, misalnya, PPMI, GloVe, dan model berbasis prediksi, misalnya, SGNS, BERT) ke vektor yang dibuat dari peringkat manusia. Vektor berbasis manusia diambil dari dataset Binder (Binder et al., 2016 ), yang berisi peringkat relevansi 65 fitur semantik dengan 535 konsep. Peserta diminta untuk menilai relevansi setiap fitur semantik untuk konsep tertentu. Ke-65 fitur tersebut dipilih untuk mewakili modalitas inti pemrosesan informasi dari literatur neuroimaging. Misalnya, dataset tersebut mencakup fitur yang berfokus pada pengalaman sensorik dan motorik tertentu (misalnya, bentuk dan gerakan), serta pengalaman afektif (misalnya, senang dan sedih). Model-model tersebut diuji kemampuannya untuk memprediksi nilai-nilai pada seluruh 65 fitur untuk kata-kata yang tidak terlihat. Para penulis menemukan bahwa fitur-fitur sosial, kausal, dan kognisi secara umum diprediksi lebih baik daripada fitur-fitur sensorimotor, yang konsisten dengan gagasan bahwa bahasa merupakan sumber informasi penting untuk jenis-jenis fitur semantik ini (Borghi et al., 2019 ). Dalam domain persepsi, beberapa fitur somatosensori diprediksi dengan baik (seperti warna dan bentuk), sedangkan yang lain kurang tertangkap dengan baik (seperti terang dan gelap) (Chersoni et al., 2021 ).
Sejumlah penelitian lain telah menggunakan kumpulan data Binder untuk menyelidiki pengetahuan yang direpresentasikan dalam word embeddings. Turton dan koleganya ( 2020, 2021 ) menggunakan Word2Vec dan BERT embeddings untuk memprediksi vektor pemeringkatan fitur dalam kumpulan data Binder, menemukan bahwa beberapa fitur persepsi kembali diprediksi dengan baik (seperti warna dan bentuk), tetapi yang lain kurang terwakili dengan baik (seperti cerah, gelap, dan lambat). Mereka juga menunjukkan bahwa pemetaan yang dipelajari antara word embeddings dan vektor pemeringkatan fitur dapat diekstrapolasi ke kosakata yang lebih luas daripada kumpulan data asli, sambil menjaga hubungan semantik antara fitur tetap utuh. Utsumi ( 2020 ) melakukan eksperimen serupa yang mengevaluasi pemetaan antara vektor pemeringkatan fitur dari kumpulan data Binder dan word embeddings menggunakan tiga jenis distributional embeddings (SGNS, GloVe, dan PPMI) yang diturunkan dari pelatihan pada dua korpora yang berbeda (COCA dan Wikipedia). Mirip dengan Chersoni et al. ( 2021 ), mereka menemukan bahwa fitur sosial, kausal, dan kognisi diprediksi dengan lebih baik, dengan fitur persepsi cenderung tidak terwakili dalam penyematan kata. Misalnya, fitur yang berkaitan dengan kecerahan atau kecepatan suatu konsep diprediksi dengan buruk. Namun, Utsumi menyimpulkan bahwa beberapa kemampuan untuk memprediksi informasi persepsi hadir untuk domain seperti bentuk, penglihatan, dan suara. Utsumi ( 2020 ) juga menyelidiki kinerja prediksi secara terpisah antara konsep konkret dan abstrak. Prediksi lebih buruk untuk kata-kata abstrak di semua jenis fitur, kecuali untuk fitur emosi. Mungkin tidak mengherankan, fitur persepsi diprediksi sangat buruk untuk kata-kata abstrak, konsisten dengan pandangan lama bahwa konsep abstrak memiliki sedikit asosiasi persepsi (Paivio, 1990 ). Secara keseluruhan, studi-studi ini memberikan beberapa bukti bahwa penyematan dapat memprediksi beberapa jenis informasi persepsi yang terkait dengan konsep, meskipun prediksi fitur persepsi murni lebih buruk daripada jenis informasi semantik lainnya.
Bahasa Indonesia: Mengapa kualitas perseptual tampaknya kurang terwakili dengan baik dalam penanaman kata? Di bagian sebelumnya, kami mencatat bahwa keterlibatan pemrosesan perseptual selama pemahaman bahasa sangat bergantung pada konteks. Namun, metode distribusional tradisional untuk memperoleh penanaman kata (misalnya, Word2Vec, GloVe) telah didekontekstualisasikan (juga dikenal sebagai “statis”). Ini berarti bahwa seluruh representasi kata dikodekan sebagai vektor tunggal, yang diabstraksikan di semua konteks berbeda tempat kata tersebut digunakan. Dengan demikian, penanaman statis menangkap properti dan hubungan semantik paling signifikan yang paling andal direpresentasikan di seluruh konteks. Ini berarti bahwa informasi yang kurang menonjol, seperti kualitas perseptual, mungkin tidak terwakili dengan baik. Namun, kemajuan lebih lanjut dalam pembelajaran mesin telah mengarah pada LLM berbasis Transformer, di mana penanaman kata berubah tergantung pada konteks linguistik tempat kata itu disajikan (Vaswani et al., 2017 ). Model-model ini memiliki penyematan yang lebih canggih dengan potensi untuk mengodekan informasi spesifik konteks, seperti arti kata yang berbeda dan properti yang relevan secara kontekstual. Para peneliti telah mulai menguji kemampuan prediktif penyematan kata kontekstual menggunakan model BERT berbasis Transformer (Devlin et al., 2018 ). Turton, Smith, dan Vinson ( 2021 ) membuat penyematan BERT untuk konsep dengan mengambil sampel 250 kalimat yang berisi setiap kata dalam dataset Binder. Kalimat-kalimat ini dimasukkan ke dalam BERT, menyediakan 250 penyematan kata kontekstual yang berbeda untuk setiap kata target. Representasi tunggal bebas konteks kemudian diperoleh untuk setiap kata dengan menghitung rata-rata dari 250 penyematannya (untuk pendekatan serupa, lihat Chersoni et al., 2021 ; Bommasani, Davis, & Cardie, 2020 ; Vulić, Ponti, Litschko, Glavaš, & Korhonen, 2020 ). ( 2021 ) menemukan bahwa penyematan BERT yang dibuat dengan cara ini mengungguli penyematan statis dalam memprediksi vektor peringkat fitur dari Binder et al. ( 2016 ), yang menunjukkan bahwa hanya dengan menggabungkan penyematan pada banyak konteks menghasilkan representasi yang lebih baik dalam menangkap pengalaman manusia dengan konsep. Mereka kemudian menunjukkan bahwa pemilihan 10 kalimat yang sesuai dengan arti kata seperti yang digunakan dalam kumpulan data Binder meningkatkan hasil ini lebih jauh.
Manfaat dari penyematan kontekstual juga ditunjukkan saat menilai efek konteks tertentu. Di sini, Turton dan rekan-rekannya ( 2021 ) menggunakan kumpulan data peringkat fitur semantik untuk pasangan properti–objek (misalnya, “lava abrasif”; “amplas abrasif”; Van Dantzig, Cowell, Zeelenberg, & Pecher, 2011 ) untuk menyelidiki bagaimana keberadaan konteks tertentu memengaruhi kinerja prediksi. Dalam studi asli, peserta diminta untuk memberikan peringkat pada lima skala terpisah yang mewakili setiap modalitas persepsi dalam menjawab pertanyaan: “Sejauh mana Anda mengalami [objek] menjadi [properti]” (Van Dantzig et al., 2011 ). Turton dan rekan-rekannya pertama-tama memasukkan pasangan properti–objek ke dalam model Transformer dan mengekstrak penyematan kata untuk kata-kata properti dalam konteks objek tertentu. Mereka kemudian membandingkan kinerja embedding ini terhadap embedding properti yang dirata-ratakan (yaitu, dirata-ratakan di dua konteks objek) dan embedding Numberbatch baseline statis dalam memprediksi peringkat fitur untuk pasangan properti–objek (Speer, Chin, & Havasi, 2017 ). Misalnya, mereka membandingkan seberapa baik embedding yang diekstraksi untuk “abrasif” memprediksi peringkat fitur persepsi untuk “lava abrasif” dan “amplas abrasif.” Mereka menemukan bahwa embedding Transformer yang dikontekstualisasikan mengungguli embedding Transformer rata-rata dan embedding Numberbatch. Studi ini memberikan indikasi pertama bahwa mengontekstualisasikan embedding dengan kasus penggunaan tertentu dapat mengarah pada prediksi properti persepsi yang lebih efektif. Dalam studi saat ini, kami membangun ide ini dalam dua eksperimen. Dalam percobaan pertama, kami menyelidiki apakah prediksi penilaian yang dihasilkan manusia pada sifat persepsi kata benda ditingkatkan ketika penyematan kontekstual dihasilkan menggunakan konteks yang secara khusus menjadi dasar untuk fitur persepsi yang diinginkan (misalnya, “kecerahan arang,” “bentuk arang”). Kami menyelidiki kedua penilaian pada relevansi fitur dengan kata benda (baik kecerahan atau bentuk), dan penilaian pada kecerahan kata benda yang dirasakan. Dalam percobaan kedua, kami memperluas ini ke frasa kata sifat-kata benda (misalnya, “arang gelap”), yang jarang dipelajari. Di sini, kami mencoba untuk memprediksi penilaian kecerahan yang dirasakan dari kombinasi konseptual. Kami menguji apakah penyematan kontekstual lebih baik memprediksi penilaian persepsi frasa tersebut dan apakah model bahasa menyusun makna frasa kata sifat-kata benda dengan cara yang sama seperti manusia.
2 Percobaan 1
Dalam Eksperimen 1, kami membandingkan kinerja penempatan kata yang dikontekstualisasikan dan yang didekontekstualisasikan untuk mengetahui seberapa baik keduanya dapat memprediksi penilaian kualitas persepsi kata benda yang dibuat manusia. Kami mengeksplorasi kinerja prediksi penempatan kata dari Model Semantik Distribusional (Word2Vec) dan Model Bahasa Besar (BERT). Kami menyelidiki masalah ini menggunakan dua fitur persepsi spesifik sebagai kasus uji: kecerahan dan bentuk. Kami memilih kecerahan karena belum diprediksi dengan baik dalam penelitian sebelumnya (Chersoni et al., 2021 ; Utsumi, 2020 ), dan, oleh karena itu, merupakan kasus uji yang menantang untuk memeriksa sejauh mana representasi fitur persepsi dalam penempatan. Ini berbeda dengan bentuk, yang telah diprediksi dengan baik (Chersoni et al., 2021 ; Turton et al., 2021 ; Utsumi, 2020 ). Kami juga memilih kecerahan karena memungkinkan kami memanfaatkan kumpulan data penting yang berisi peringkat untuk kata benda yang tidak dimodifikasi, dan kombinasi kata sifat–kata benda (kumpulan data Solomon dan Thompson-Schill), yang memungkinkan kami mengeksplorasi sifat kombinasi konseptual dalam konteks.
Pertama, kami menggunakan peringkat terang dan gelap dari kumpulan data Binder, yang paling umum digunakan dalam penelitian sebelumnya tentang topik ini (Chersoni et al., 2021 ; Turton et al., 2020, 2021 ; Utsumi, 2020 ). Binder et al. ( 2016 ) memperoleh peringkat untuk banyak fitur berbeda sehingga kumpulan data ini berisi sejumlah besar item yang kecerahannya bukan fitur yang menonjol (misalnya, “kursi”) atau relevan (misalnya, “keunggulan”). Kedua, kami menggunakan kumpulan data kecerahan Solomon dan Thompson-Schill ( 2020 ). S&T-S hanya mengeksplorasi kecerahan dan, oleh karena itu, mereka mengumpulkan peringkat untuk sekumpulan konsep yang lebih kecil yang kecerahan/kegelapannya merupakan fitur yang relevan dan menonjol (misalnya, “berlian,” “abu-abu,” “arang”). Dengan membandingkan prediksi persepsi di kedua set data ini, kami dapat menguji sejauh mana temuan dari set data Binder dapat digeneralisasi ke set data lain, yang disesuaikan dengan fitur spesifik yang sedang diselidiki. Sebagai perbandingan, kami juga memperkirakan peringkat pada relevansi bentuk dengan konsep. Kami memilih fitur persepsi ini karena sebelumnya telah dilaporkan diprediksi dengan baik oleh penyematan BERT (Chersoni et al., 2021 ; Turton et al., 2020 ). Kami menggunakan peringkat Binder untuk penyelidikan ini.
Gambar 1 menunjukkan ikhtisar alur percobaan kami. Untuk penyematan Word2Vec, kami mengekstrak representasi penyematan kata benda dari model Google yang telah dilatih sebelumnya yang dilatih pada bagian set data Google News (Mikolov et al., 2013 ; Mikolov et al., 2013 ). Kami kemudian menggunakan penyematan ini sebagai input ke jaringan saraf umpan maju untuk memprediksi peringkat fitur persepsi untuk kata benda tersebut. Word2Vec menghasilkan representasi tunggal dari setiap kata dan, oleh karena itu, penyematan ini didekontekstualisasikan dan statis. Sebaliknya, kami menggunakan kapasitas BERT untuk kontekstualisasi saat mengekstrak penyematan BERT kami. Di sini, kami menggunakan model Google yang telah dilatih sebelumnya, mengekstrak penyematan dari model dasar BERT dan model besar BERT, yang berbeda dalam dimensionalitas (Devlin et al., 2018 ). Bahasa Indonesia: Mengikuti studi sebelumnya, kami menyertakan kondisi bebas konteks, yang berisi penanaman BERT yang dirata-ratakan dari beberapa konteks kalimat (Bommasani et al., 2020 ; Chersoni et al., 2021 ; Turton et al., 2021 ; Vulić et al., 2020 ). Kondisi bebas konteks ini juga dapat dianggap sebagai prototipe karena memperoleh representasi abstrak dari setiap kata di banyak contoh berbeda (Hampton, 2015 ; Rosch & Mervis, 1975 ). Untuk melakukan ini, kami mengidentifikasi 250 kalimat yang berisi kata benda yang diinginkan dari korpus Tolok Ukur Satu Miliar Kata (Chelba et al., 2014 ). Kami kemudian mengekstrak penanaman BERT untuk kata benda di setiap kalimat dan merata-ratakannya. Kami juga memiliki kondisi yang diminta secara kontekstual, di mana kami menyertakan permintaan kontekstual yang ditargetkan pada fitur persepsi yang diinginkan. Untuk penyelidikan kecerahan, kami menggunakan dua perintah berbeda, “kecerahan…” dan “warna…”; sementara kami hanya menggunakan satu perintah untuk penyelidikan bentuk: “bentuk…” Kami secara terpisah menyajikan perintah ini ke BERT dan mengekstraksi penyematan untuk kata benda. Jika kontekstualisasi penyematan BERT menghasilkan penyematan yang selaras dengan penilaian manusia tentang fleksibilitas konseptual, kami akan mengharapkan penyematan BERT yang diminta secara kontekstual untuk memprediksi fitur persepsi yang diinginkan dengan lebih baik, dibandingkan dengan penyematan Word2Vec dan BERT bebas konteks.

2.1 Metode
Semua kode dan data terkait dapat diakses di sini: https://osf.io/ca4wm/
2.1.1 Kumpulan Data
Kami mengevaluasi kinerja model dalam memprediksi penilaian manusia terhadap kualitas persepsi dari dua set data. Dalam set data Solomon dan Thompson-Schill (S&T-S) , 1 Solomon dan Thompson-Schill ( 2020 ) meminta partisipan untuk menilai kecerahan 45 kata benda pada skala 0–50 (paling terang hingga paling gelap), dengan atau tanpa pengubah. Partisipan ( n = 100) membuat penilaian ini dengan menggerakkan penggeser, dengan batang yang menunjukkan spektrum warna skala abu-abu mulai dari 0 (putih) hingga 50 (hitam). Kami menskalakan penilaian agar berada di antara 0 dan 1 (paling terang hingga paling gelap). Kata benda dalam set data ini secara khusus dipilih untuk mewakili seluruh spektrum nilai kecerahan (misalnya, “arang” vs. “salju”), dan untuk menyertakan konsep yang kecerahannya merupakan fitur relevan. Kami menghapus tiga kata sifat dari set data asli untuk fokus hanya pada kata benda (“hitam,” “putih,” dan “abu-abu”). Para penulis juga mengumpulkan peringkat untuk versi yang dimodifikasi kata sifat untuk setiap kata benda, yang kami gunakan dalam Eksperimen 2.
Kumpulan data Binder 2 terdiri dari peringkat semantik yang dikumpulkan oleh Binder et al. Di sini, penulis bertujuan untuk membuat kumpulan data peringkat fitur konseptual yang diinformasikan oleh modalitas pemrosesan informasi saraf yang diketahui. Penulis menetapkan 65 fitur semantik. Peserta ( n = 1743 ) diminta untuk menilai relevansi setiap fitur semantik dengan makna sebuah kata pada skala 1 hingga 6. Setiap peserta diberi satu kata dan memberikan peringkat untuk semua 65 fitur. Karena tugas ini bersumber dari banyak orang di Amazon Mechanical Turk, penulis menyertakan metrik kualitas untuk memastikan bahwa peserta fokus pada tugas. Dengan demikian, korelasi antara vektor peserta dan vektor rata-rata kelompok sebuah kata dihitung dan jika ini tidak melebihi nilai minimum r = .5, peserta dibuang. Kumpulan data Binder asli menyertakan dua fitur yang terkait dengan kecerahan suatu konsep: peringkat pada tingkat di mana setiap konsep secara visual cerah atau gelap. Untuk mengubah fitur-fitur ini menjadi metrik kecerahan yang mirip dengan yang digunakan dalam dataset S&T-S, pertama-tama kami menskalakan setiap dimensi antara 0 dan 1, mengurangi dimensi gelap yang diskalakan dari dimensi cerah yang diskalakan, lalu mengubah output untuk memastikan bahwa semua nilai jatuh antara 0 dan 1. Dengan cara ini, spektrum peringkat kecerahan meniru Solomon dan Thompson-Schill, sehingga kata-kata yang secara stereotip cerah (misalnya, “matahari”) memiliki peringkat rendah (0,133), sedangkan kata-kata yang secara stereotip gelap (misalnya, “gagak”) memiliki peringkat tinggi (0,949). Penting untuk dicatat bahwa Solomon dan Thompson-Schill ( 2020 ) secara khusus memilih item yang kecerahannya merupakan properti yang sangat relevan. Sebaliknya, dataset Binder mencakup banyak item yang tidak terkait kuat dengan tingkat kecerahan tertentu; oleh karena itu, banyak item dikelompokkan di sekitar titik tengah spektrum kecerahan. Untuk fitur persepsi kedua kami, bentuk, kami juga menggunakan peringkat dari dataset Binder.
Kami menggunakan dua versi dataset Binder, satu yang hanya berisi kata benda konkret dan yang lainnya berisi kata benda abstrak dan konkret. Versi konkret dari dataset dibuat dengan memfilter dataset asli berdasarkan jenis dan kategori super. Kami memfilter jenis agar hanya berisi item yang digolongkan sebagai “benda” atau “peristiwa”, dengan kategori super difilter agar menyertakan “artefak”, “objek hidup”, “objek alami”, dan “keadaan fisik”. Ini menghasilkan dataset berisi 274 kata benda konkret. Untuk investigasi yang menyertakan item abstrak, kami juga memfilter kategori super berdasarkan “entitas abstrak”, “peristiwa”, dan “entitas mental”. Ini menghasilkan dataset berisi 433 item, dengan 275 item konkret dan 159 item abstrak. Kami memilih untuk mengeksplorasi kinerja konsep konkret saja karena Utsumi ( 2020 ) menemukan kinerja yang buruk untuk prediksi sifat persepsi untuk konsep abstrak. Oleh karena itu, kami ingin menguji efek dari pengecualian ini.
2.1.2 Penanaman
Kami menggunakan tiga set penempatan kata yang telah dilatih sebelumnya: Word2Vec, BERTbase, dan BERTLarge. Hal ini memungkinkan kami untuk membuat perbandingan antara penempatan kata yang dapat memanfaatkan informasi kontekstual (dikontekstualisasikan) versus yang statis dan independen dari konteks (didekontekstualisasikan). Selain itu, kami secara khusus menggunakan penempatan yang telah dilatih sebelumnya, daripada melatih milik kami sendiri, karena kami ingin menilai kemampuan prediktif penempatan yang tersedia untuk umum yang dapat digunakan peneliti untuk menjelaskan representasi konseptual kata-kata (Günther, Rinaldi, & Marelli, 2019 ; Pereira, Gershman, Ritter, & Botvinick, 2016 ). Kami juga menyertakan vektor one-hot sebagai perbandingan dasar untuk setiap percobaan untuk menguji pengaruh pelatihan jaringan saraf feedforward kami. Di sini, setiap kata dikodekan sebagai vektor yang panjangnya sama dengan jumlah kata dalam kosakata. Untuk representasi satu kata, simpul yang terkait dengan kata tersebut (misalnya, “arang”) akan “aktif”, sementara semua simpul lainnya dimatikan. Dengan demikian, vektor one-hot merepresentasikan skema pengkodean leksikal sederhana yang tidak mengandung informasi semantik.
Embedding Word2Vec adalah contoh embedding kata statis, yang berarti embedding tersebut menetapkan vektor tetap untuk setiap kata, terlepas dari konteks penggunaan kata tersebut (Mikolov et al., 2013 ). Kami menggunakan embedding yang telah dilatih sebelumnya dari model Word2Vec yang dilatih pada bagian set data Google News (∼100 miliar kata). Dimensionalitas embedding adalah d = 300, dan bukti sebelumnya menunjukkan bahwa embedding tersebut sangat sesuai dengan penilaian semantik manusia dalam berbagai tugas (Pereira et al., 2016 ). Rincian lebih lanjut tentang embedding yang telah dilatih sebelumnya ini dapat ditemukan di Google Code Archive ( https://code.google.com/archive/p/word2vec/ ).
Embedding BERT adalah contoh embedding kata kontekstual dan diekstraksi dari BERT (Bidirectional Encoder Representations from Transformers), Large Language Model (LLM) berdasarkan arsitektur Transformer (Devlin et al., 2018 ). Model dilatih pada tugas pemodelan bahasa bertopeng, di mana sampel bahasa diberikan 15% kata yang ditopeng secara acak dan model dilatih untuk memprediksi kata-kata bertopeng. Kami menggunakan HuggingFace Transformers API untuk mengakses dua model pra-latih yang berbeda, yang berbeda dalam ukuran (bert-base-uncased dan bert-large-uncased) (Wolf et al., 2020 ). Model-model ini dilatih sebelumnya pada dua korpora (∼3 miliar kata), BookCorpus dan English Wikipedia, dan ditokenisasi menggunakan WordPiece, algoritma tokenisasi berbasis subkata. Kami mengekstraksi penempatan kata yang sesuai dari lapisan tersembunyi terakhir, dan jika kata benda dipecah menjadi subkata terpisah, kami mengekstraksi penempatan subkata dan merata-ratakannya untuk mewakili keseluruhan kata (dimensi: BERTbase : d = 768; BERTLarge : d = 1024). Kami memilih untuk mengekstraksi penempatan dari lapisan tersembunyi terakhir karena penelitian sebelumnya telah menunjukkan bahwa fitur semantik direpresentasikan dengan lebih baik oleh lapisan yang lebih tinggi (Jawahar, Sagot, & Seddah, 2019 ; Turton et al., 2021 ).
Bahasa Indonesia: Untuk membuat kondisi bebas konteks , kami mereplikasi metode dari Turton et al. ( 2021 ) untuk membuat versi “statis” dari penyematan BERT. Untuk setiap konsep, kami mengekstrak secara acak ∼250 kalimat yang berisi kata target dari korpus Tolok Ukur Satu Miliar Kata (Chelba et al., 2014 ) yang diakses melalui HuggingFace ( https://huggingface.co/datasets/lm1b ). Untuk melakukan ini, kami memulai dengan kata target (misalnya, “kopi”) dan partisi rangkaian acak dari korpus ( n = 30.301.028). Kami kemudian mencari melalui korpus, menggunakan pencocokan string untuk mengidentifikasi kalimat yang berisi kata target kami, dan menyimpan contoh dari 250 kalimat pertama yang ditemukan. Kalimat-kalimat ini kemudian dibersihkan untuk menghilangkan tanda baca dan spasi yang tidak relevan. Untuk setiap konsep, kami menjalankan masing-masing dari 250 kalimat korpus yang diberi token melalui BERT, menemukan posisi kata target dalam kalimat, dan mengekstraksi embedding tingkat kata (atau embedding tingkat subkata yang dirata-ratakan). Kami kemudian merata-ratakan 250 embedding tersebut, yang digunakan sebagai input ke jaringan saraf kami.
Untuk membuat kondisi yang diminta secara kontekstual , kami membuat permintaan khusus untuk kata benda tergantung pada fitur yang akan diprediksi. Untuk kecerahan, kami awalnya menggunakan “kecerahan [kata benda].” Namun, frasa ini dapat dianggap agak tidak biasa dan tidak alami untuk beberapa konsep dalam kumpulan data (misalnya, kebanyakan orang akan menggambarkan burung gagak berwarna gelap, bukan gelap dalam kecerahan). Karena itu, kami juga menguji permintaan kedua, “warna [kata benda],” yang dua kali lebih sering muncul dalam korpus n-gram Google. 3 Kami menyajikan hasil dari kedua permintaan dan menggunakan permintaan dengan kinerja terbaik dalam perbandingan dengan penyematan lainnya. Untuk memprediksi bentuk, kami menggunakan “bentuk [kata benda].” Kami kemudian menjalankan frasa tokenisasi ini melalui BERT, menemukan kata target di akhir frasa, dan mengekstrak penyematan tingkat kata (atau penyematan tingkat subkata yang dirata-ratakan) sebagai masukan ke jaringan saraf kami. Dengan demikian, kami memiliki tiga versi kondisi yang diminta secara kontekstual: kecerahan, warna, dan bentuk.
2.1.3 Model
Bahasa Indonesia: Mengikuti pendekatan yang serupa dengan penelitian lain (Sommerauer & Fokkens, 2018 ; Turton et al., 2020, 2021 ; Utsumi, 2020 ), kami melatih jaringan saraf umpan maju tiga lapis untuk memprediksi peringkat fitur manusia dari penyematan kata kami. Model tersebut diimplementasikan dalam PyTorch (Paszke et al., 2019 ) dan terdiri dari lapisan masukan (dimensi bergantung pada penyematan masukan), fungsi aktivasi ReLU, lapisan putus sekolah dengan p = .2, lapisan tersembunyi (dimensi bergantung pada jenis investigasi), dan unit keluaran tunggal ( d = 1) dengan fungsi aktivasi sigmoid untuk menormalkan prediksi antara 0 dan 1. Untuk prosedur pelatihan kami, kami menggunakan k -fold cross-validation di mana k = 10. Di setiap lipatan, model dilatih dengan 90% konsep dan kemudian diuji kemampuannya untuk memprediksi fitur relevan untuk 10% konsep yang tersisa. Hiperparameter yang digunakan untuk pelatihan model adalah: laju pembelajaran = 0,01, bias = –2, momentum = 0,9, dan penurunan bobot = 10 −6 . Kami mengoptimalkan menggunakan penurunan gradien stokastik. Kami juga melakukan penyetelan hiperparameter untuk jumlah unit tersembunyi dan jumlah periode untuk pelatihan, menggunakan pencarian grid dan validasi silang bersarang ( k = 3). Kami mempertahankan hiperparameter yang disetel sama di seluruh perbandingan eksperimen tertentu untuk memastikan kewajaran.
2.1.4 Evaluasi
Bahasa Indonesia: Untuk mengurangi gangguan acak, untuk setiap investigasi, 10 model berbeda diinisialisasi dengan bobot awal acak. Masing-masing dari 10 model dilatih dan diuji menurut skema validasi silang 10 kali lipat yang dijelaskan sebelumnya. Perbedaan kinerja model di 10 implementasi itu kecil (simpangan baku kesalahan di seluruh model disajikan dalam Materi Tambahan). Kami memperoleh prediksi tunggal untuk setiap konsep dengan merata-ratakan prediksi 10 model. Kami mengevaluasi kinerja penyematan yang berbeda menggunakan mean squared error (MSE) dan R 2 . MSE dihitung sebagai rata-rata kesalahan kuadrat antara prediksi model dan peringkat manusia untuk setiap konsep. R 2 untuk korelasi antara prediksi model dan peringkat manusia dihitung dengan menyesuaikan model regresi kuadrat terkecil biasa. Selain itu, kami menjalankan uji statistik pada perbandingan yang diinginkan untuk kecerahan dan bentuk, yang diuraikan di bawah ini. Untuk mengevaluasi perbandingan ini, kami menggunakan uji peringkat bertanda Wilcoxon, yang merupakan uji nonparametrik sampel berpasangan, yang membandingkan kesalahan kuadrat untuk setiap kata benda. Untuk bentuk dan kecerahan, kami membandingkan:
- Word2Vec versus BERT bebas konteks
- BERT bebas konteks versus BERT yang diminta secara kontekstual
- Untuk percobaan kecerahan, kami juga membandingkan:
- “Kecerahan” didorong secara kontekstual BERT versus “warna” didorong secara kontekstual BERT
- Untuk eksperimen menggunakan dataset Binder, kami juga membandingkan kinerja untuk:
- Kecerahan versus bentuk
2.2 Hasil
2.2.1 Dataset Solomon dan Thompson-Schill
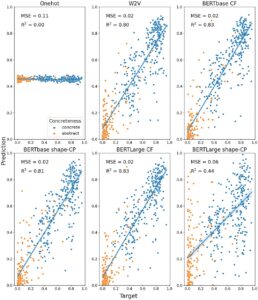
Gambar 2 menyajikan ikhtisar hasil kata benda untuk setiap penanaman pada dataset S&T-S, bersama dengan MSE dan R 2 .
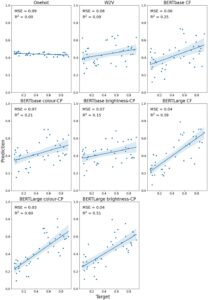
Seperti yang diharapkan, model yang dilatih dengan vektor one-hot yang tidak mengandung informasi semantik tidak dapat memprediksi kecerahan konsep target. Nilai kecerahan yang diprediksi dalam model ini terkelompok ketat di sekitar 0,5 dan tidak terkait dengan kecerahan konsep target. Model yang dilatih dengan embedding berkinerja lebih baik. Secara umum, embedding BERTLarge tampaknya memiliki kinerja terbaik, dengan nilai R 2 berkisar dari 0,5 hingga 0,6. Jadi, meskipun penelitian sebelumnya telah melaporkan prediksi kecerahan/kegelapan yang buruk, di sini kami menemukan bahwa embedding dapat memprediksi ini sampai batas yang wajar. Ini mungkin karena kami berfokus terutama pada serangkaian kata benda yang kecerahannya merupakan fitur yang sangat relevan. Tabel 1 menyajikan ikhtisar kinerja rata-rata untuk setiap jenis embedding. Skor MSE dan deviasi standar untuk setiap putaran model dapat ditemukan di Materi Tambahan.
| MSE | R 2 | |
|---|---|---|
| Satu Panas | 0,09 | .00 |
| Kata2Vec | 0,08 | .09 |
| BERTbase bebas konteks | 0,06 | .25 |
| BERTbase diminta berdasarkan konteks warna | 0,07 | .21 |
| BERTbase kecerahan diminta secara kontekstual | 0,07 | .15 |
| BERTLarge bebas konteks | 0,04 | .59 |
| BERTLarge diminta berdasarkan konteks warna | 0,03 | .60 |
| BERTLarge kecerahan-diminta secara kontekstual | 0,04 | .51 |
Bahasa Indonesia: Untuk penyematan yang didekontekstualisasikan, kami menemukan bahwa penyematan BERTLarge bebas konteks berkinerja secara signifikan lebih baik daripada Word2Vec ( p = 6,97 × 10 −6 ). Ini juga berlaku untuk penyematan BERTbase bebas konteks, tetapi pada tingkat yang lebih rendah ( p = .04). Beralih ke penyematan yang diminta secara kontekstual, kami tidak menemukan perbedaan yang signifikan antara jenis perintah (“warna” vs. “kecerahan”) untuk BERTbase ( p = .20) atau BERTLarge ( p = .37). Karena itu, kami memilih untuk membandingkan perintah kontekstual “warna” untuk perbandingan kami dengan penyematan bebas konteks karena R 2 lebih tinggi. Kami tidak menemukan perbedaan yang signifikan antara kondisi yang diminta secara kontekstual dan bebas konteks untuk BERTbase ( p = .33) atau BERTLarge ( p = .66). Hal ini menunjukkan penambahan perintah kontekstual tidak meningkatkan kinerja untuk memprediksi kecerahan pada kumpulan data S&T-S.
2.2.2 Dataset Binder: Kecerahan
Gbr. 3 (hanya kata benda konkret) dan Gbr. 4 (kata benda konkret dan abstrak) menyajikan MSE dan R 2 untuk setiap penyematan saat model dilatih untuk memprediksi kecerahan untuk kumpulan data Binder. Secara umum, kedua konfigurasi kumpulan data menghasilkan pola hasil yang serupa. Secara keseluruhan, penyematan dengan kinerja terbaik adalah kondisi BERTbase bebas konteks dengan kata benda konkret dan abstrak (MSE = 0,01, R 2 = 0,23).
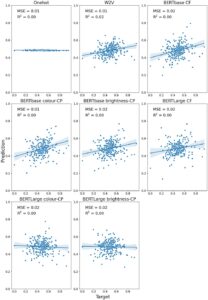
Secara keseluruhan, kami menemukan kinerja yang lebih buruk di seluruh jenis penyematan saat memprediksi kecerahan dalam dataset Binder dibandingkan dengan dataset ST&S (lihat Tabel 2 ; R2 maksimum = .23 vs. .60). Hal ini menunjukkan bahwa informasi kecerahan tidak terwakili dengan baik dalam penyematan untuk dataset yang lebih besar ini yang berisi banyak item yang kecerahannya bukan merupakan properti yang sangat relevan.
| MSE | R 2 | |
|---|---|---|
| Satu Panas | ||
| Konkret | 0,01 | .00 |
| Beton+abstrak | 0,01 | .01 |
| Kata2Vec | ||
| Konkret | 0,01 | .02 |
| Beton+abstrak | 0,01 | .11 |
| BERTbase bebas konteks | ||
| Konkret | 0,02 | .00 |
| Beton+abstrak | 0,01 | .23 |
| BERTbase diminta berdasarkan konteks warna | ||
| Konkret | 0,01 | .00 |
| Beton+abstrak | 0,01 | .20 |
| BERTbase kecerahan diminta secara kontekstual | ||
| Konkret | 0,02 | .00 |
| Beton+abstrak | 0,01 | .17 |
| BERTLarge bebas konteks | ||
| Konkret | 0,02 | .00 |
| Beton+abstrak | 0,01 | .11 |
| BERTLarge diminta berdasarkan konteks warna | ||
| Konkret | 0,02 | .00 |
| Beton+abstrak | 0,02 | .00 |
| BERTLarge kecerahan-diminta secara kontekstual | ||
| Konkret | 0,02 | .00 |
| Beton+abstrak | 0,02 | .00 |
Bahasa Indonesia: Dalam perbandingan kami tentang embeddings decontextualized, kami menemukan bahwa embedding BERT bebas konteks mengungguli Word2Vec pada dataset konkret+abstrak untuk embedding BERTbase ( p = .005) dan BERTLarge ( p = .05). Namun, ini bukan kasus untuk dataset konkret saja (dasar: p = .33; besar: p = .34). Ini menunjukkan bahwa peningkatan kemampuan prediktif dari embedding BERT bebas konteks atas Word2Vec mungkin berasal dari prediksi konsep abstrak yang lebih baik dalam dataset ini. Untuk perbandingan prompt dalam kondisi prompt kontekstual kami, kami menemukan bahwa embedding dengan prompt kontekstual “warna” berkinerja lebih baik daripada embedding dengan prompt kontekstual “kecerahan” untuk embedding BERT dalam banyak kasus, meskipun ini hanya signifikan untuk dataset konkret saja BERTbase ( p = .01). Dengan demikian, kami menggunakan embedding yang diminta “warna” untuk perbandingan statistik kami dengan embedding bebas konteks. Kami menemukan perbedaan statistik antara kondisi bebas konteks dan yang diminta kontekstual untuk embedding BERTLarge (konkret: p = .02; konkret+abstrak: p = 2,48 × 10 −7 ), tetapi bertentangan dengan harapan, embedding bebas konteks memiliki kinerja prediksi yang lebih baik. Selain itu, untuk versi BERTbase, kami tidak menemukan perbedaan statistik dalam kinerja prediksi (konkret: p = .09; konkret+abstrak: p = .96).
2.2.3 Dataset Binder: Bentuk
Selanjutnya, kita beralih ke perbandingan untuk memprediksi relevansi bentuk untuk berbagai konsep. Lihat Gambar 5 (hanya konkret) dan Gambar 6 (konkret+abstrak) untuk tinjauan umum MSE dan R 2 untuk penelitian ini.
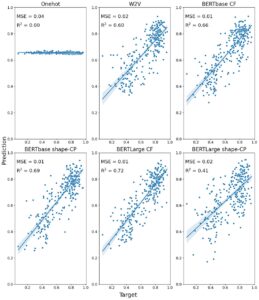
Seperti yang diharapkan, berdasarkan studi sebelumnya, embedding menghasilkan performa yang sangat baik dalam memprediksi relevansi bentuk (Turton et al., 2021 ; Utsumi, 2020 ). Tinjauan umum performa embedding disajikan dalam Tabel 3. Embedding dengan performa terbaik adalah embedding BERT bebas konteks pada dataset konkret+abstrak, tanpa perbedaan performa antara versi dasar dan versi besar (dasar: MSE = 0,02, R2 = 0,83; Besar: MSE = 0,02, R2 = 0,83). Secara umum, penambahan kata benda abstrak meningkatkan performa model untuk sebagian besar tipe embedding. Ini kemungkinan terkait dengan fakta bahwa nilai bentuk untuk konsep abstrak mengelompok di ujung bawah spektrum. Perbedaan kuat antara kata benda konkret dan abstrak ini mungkin telah membantu bootstrap learning dari pemetaan antara kata benda dan relevansi bentuk.
| MSE | R 2 | |
|---|---|---|
| Satu Panas | ||
| Konkret | 0,04 | .00 |
| Beton+abstrak | 0.11 | .00 |
| Kata2Vec | ||
| Konkret | 0,02 | .60 |
| Beton+abstrak | 0,02 | .80 |
| BERTbase bebas konteks | ||
| Konkret | 0,01 | .66 |
| Beton+abstrak | 0,02 | .83 |
| Bentuk BERTbase diminta secara kontekstual | ||
| Konkret | 0,01 | .69 |
| Beton+abstrak | 0,02 | .81 |
| BERTLarge bebas konteks | ||
| Konkret | 0,01 | .72 |
| Beton+abstrak | 0,02 | .83 |
| Bentuk BERTLarge diminta secara kontekstual | ||
| Konkret | 0,02 | .41 |
| Beton+abstrak | 0,06 | .44 |
Bahasa Indonesia: Melihat pada penyematan yang didekontekstualisasikan, kami menemukan perbedaan signifikan antara penyematan Word2Vec dan BERT untuk sebagian besar kondisi, dengan penyematan BERT bebas konteks berkinerja sedikit lebih baik daripada penyematan Word2Vec (dasar: konkret+abstrak: p = .004; besar: konkret: p = .002; konkret+abstrak: p = .02). Ini bukan kasus untuk penyematan BERTbase pada set data konkret saja ( p = .23). Selain itu, dalam perbandingan kami antara penyematan BERT bebas konteks dan yang diminta secara kontekstual, kami menemukan bahwa penyematan BERTLarge bebas konteks memiliki kinerja prediksi yang jauh lebih besar daripada penyematan yang diminta secara kontekstual (konkret: p = 9,64 × 10 −9 ; konkret+abstrak: p = 4,33 × 10 −18 ). Namun, tren ini tidak tampak pada penyematan BERTbase (konkret: p = .21; konkret+abstrak: p = .06). Dengan demikian, tampaknya penambahan perintah khusus fitur dapat menyebabkan kinerja prediksi yang lebih buruk untuk fitur persepsi bentuk.
Akhirnya, kami juga secara statistik membandingkan penyematan dengan performa terbaik untuk fitur kecerahan dan bentuk pada kedua konfigurasi kumpulan data. Untuk kumpulan data konkret saja, kami memilih penyematan BERTbase bebas konteks untuk kecerahan dan penyematan BERTLarge bebas konteks untuk bentuk. Di sini, tidak ada perbedaan signifikan dalam performa ( p = .63). Untuk kumpulan data konkret dan abstrak, kami memilih penyematan BERTbase bebas konteks untuk kedua fitur. Di sini, kami menemukan perbedaan signifikan antara performa, dengan performa prediksi yang lebih baik untuk bentuk daripada untuk kecerahan ( p = .01). Ini menunjukkan bahwa bentuk adalah fitur persepsi yang lebih terwakili dalam jenis penyematan kata ini daripada kecerahan, yang konsisten dengan hasil sebelumnya (Turton et al., 2020, 2021 ).
2.3 Pembahasan
Bahasa Indonesia: Dalam Eksperimen 1, kami menemukan prediksi kecerahan yang baik untuk dataset S&T-S, tetapi tidak untuk dataset Binder, yang menunjukkan bahwa bahkan properti perseptual yang sulit dapat diprediksi saat berfokus pada subset kata benda di mana fitur tersebut sangat menonjol. Mengulang temuan sebelumnya, kami juga menemukan kinerja prediksi yang sangat baik untuk relevansi bentuk dengan konsep (Turton et al., 2021 ; Utsumi, 2020 ). Secara umum, kami menemukan bahwa penyematan BERT bebas konteks mengungguli penyematan Word2Vec, yang sejalan dengan temuan sebelumnya bahwa representasi kontekstual yang teragregasi adalah prediktor fitur semantik yang lebih baik daripada penyematan statis (Bommasani et al., 2020 ; Turton et al., 2021 ). Namun, bertentangan dengan prediksi kami, kami menemukan penyematan yang diminta secara kontekstual sering kali berkinerja lebih buruk daripada penyematan bebas konteks. Kami mempertimbangkan alasan untuk ini dalam Diskusi Umum. Selain itu, representasi vektor one-hot sama sekali tidak dapat memprediksi peringkat persepsi apa pun, tidak seperti penempatan kata yang telah dilatih sebelumnya. Hal ini menegaskan bahwa keberhasilan dalam prediksi merupakan konsekuensi dari informasi semantik yang ada dalam penempatan kata dan bukan jaringan saraf yang kami gunakan untuk memetakan dari penempatan ke peringkat.
3 Percobaan 2
Sampai saat ini, penyematan kontekstual terutama telah diuji pada kemampuannya untuk memprediksi sifat persepsi kata benda. Namun, bagaimana penyematan ini mewakili sifat persepsi ekspresi multi-kata, seperti frasa kata sifat-kata benda, merupakan pertimbangan penting. Teori linguistik menyatakan bahwa kata sifat memodulasi sifat kata benda dan mereka sering melakukannya dengan cara yang tidak seragam (Solt, 2019 ). Secara khusus, literatur linguistik membuat perbedaan antara kata sifat subsektif yang maknanya peka terhadap konteks, dan, oleh karena itu, bergantung pada kelas perbandingan yang mereka modifikasi seperti “tinggi,” dan kata sifat intersektif yang memiliki makna yang lebih tidak peka terhadap konteks, seperti istilah warna (Demonte, 2019 ; Partee, 2007 ). Sebagai subtipe kata sifat subjektif, kata sifat yang relatif bertingkat seperti “lambat”/”tinggi” juga dicirikan oleh ketidakjelasan dan bahkan telah diteorikan untuk tidak secara langsung menunjukkan sifat. Sebaliknya, telah dikemukakan bahwa denotasi hanya diberikan makna selama proses komposisi (Kennedy, 2007, 2012 ).
Teori tradisional tentang komposisi kombinasi konseptual mencakup model modifikasi selektif, yang secara khusus berfokus pada kombinasi kata sifat–kata benda. Di sini, diasumsikan bahwa konsep direpresentasikan sebagai struktur seperti skema dengan serangkaian dimensi dan nilai yang sesuai, mirip dengan teori prototipe (Hampton, 2015 ; Rosch & Mervis, 1975 ; Rumelhart, 1980 ). Selama kombinasi, fitur utama kata sifat dibobot ulang ke konsep kata benda (Smith, Osherson, Rips, & Keane, 1988 ; Smith & Osherson, 1984 ). Namun, kritik terhadap model modifikasi selektif mencatat bahwa proses kombinasi lebih kompleks, terutama ketika diperluas ke kombinasi konseptual lain seperti gabungan kata benda–kata benda (Hampton, 2015 ; Murphy, 1988 ). Sebaliknya, pandangan spesialisasi konsep menyatakan bahwa kombinasi terjadi melalui spesialisasi konsep kata benda utama ketika salah satu “slot”-nya diisi oleh konsep pengubah (Cohen & Murphy, 1984 ; Murphy, 1988, 2004 ). Teori ini menekankan peran pengetahuan latar belakang umum dan penalaran dalam membentuk kombinasi konseptual (Murphy, 2004 ). Singkatnya, teori tentang kombinasi konseptual menggambarkan gagasan bahwa proses kombinatorial itu sendiri sangat istimewa dan bergantung pada konsep-konsep penyusunnya (Coutanche, Solomon, & Thompson-Schill, 2019 ). Ini menunjukkan bahwa frasa kata sifat-kata benda mungkin merupakan kasus khusus di mana penanaman statis tidak cukup dalam menangkap semantik yang mendasarinya, karena proses kombinasi menggeser representasi kedua kata dengan cara yang tidak dapat diprediksi.
Frasa kata sifat–kata benda adalah cara yang berharga untuk mengisolasi proses integrasi kombinasi konseptual karena mereka independen dari proses tambahan pemilihan properti. Solomon dan Thompson-Schill ( 2020 ) menunjukkan hal ini dengan meminta orang untuk menilai fitur persepsi kecerahan untuk frasa kata sifat–kata benda. Mereka menemukan bahwa kata sifat “gelap” dan “terang” mengubah persepsi orang tentang kecerahan kata benda, tetapi mereka tidak melakukannya dengan cara aditif: kata sifat memiliki lebih banyak dampak pada beberapa kata benda daripada yang lain. Misalnya, untuk kata benda dengan kecerahan sedang, seperti “cat,” ada perbedaan besar antara kecerahan yang dirasakan dari versi terangnya (“cat terang” = 0,112) dan gelap (“cat gelap” = 0,867). Untuk kata benda lain dengan persepsi kecerahan yang lebih ekstrem dan invarian, seperti “arang,” kata sifat memiliki efek yang lebih kecil (“arang terang” = 0,565; “arang gelap” = 0,930). Contoh-contoh seperti ini hadir sebagai kasus uji yang jelas di mana kita dapat bertanya apakah penyematan kontekstual memiliki keunggulan dalam prediksi persepsi, dibandingkan dengan penyematan statis, dalam menangkap interaksi kompleks antara kata sifat dan kata benda. Dengan demikian, untuk percobaan kedua kami, kami mengeksplorasi apakah penyematan kontekstual dapat secara akurat memprediksi properti untuk frasa kata sifat-kata benda yang dimodifikasi, dan apakah perintah yang ditargetkan ke properti yang relevan meningkatkan perilaku ini.
Untuk mengujinya, kami kembali menggunakan Word2Vec embeddings, contextual prompted BERT embeddings, dan context-free BERT embeddings. Untuk Word2Vec embeddings, kami mengekstrak setiap dari word2Vec embeddings kata sifat dan kata benda dan menggabungkannya untuk mewakili frasa kata sifat-kata benda. Karena kami ingin mengevaluasi prediksi untuk kata benda yang tidak dimodifikasi, di samping versi “terang” dan “gelap”, kami juga memasangkan kata benda dengan kata sifat yang tidak informatif berkenaan dengan kecerahan. Kami memilih “berat” untuk ini karena merupakan kata sifat frekuensi tinggi (mirip dengan “terang” dan “gelap”) yang dapat diterapkan pada objek, sementara tidak menyampaikan informasi tentang kecerahannya. Paradigma pelatihan kami untuk investigasi ini menguji kinerja prediksi setiap model pada frasa kata sifat-kata benda yang tidak terlihat. Untuk BERT embeddings, kami kembali membandingkan contextual prompted embeddings dengan context-free embeddings. Karena kami tertarik pada ekspresi multikata, kami menggunakan token klasifikasi BERT (CLS) untuk mewakili seluruh frasa (lihat Metode). Untuk kondisi bebas konteks, kami mengekstrak token CLS untuk frasa kata sifat-kata benda saja, sedangkan untuk kondisi yang diminta secara kontekstual, kami menggunakan token CLS untuk frasa yang diminta fitur (misalnya, “kecerahan/warna cat gelap”). Gambar 7 menyajikan ikhtisar alur percobaan kami untuk Eksperimen 2.
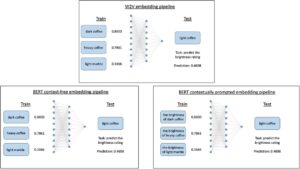
3.1 Metode
3.1.1 Kumpulan data
Kami menggunakan kumpulan data S&T-S untuk investigasi kata sifat–kata benda kami. Untuk studi ini, kami menggunakan ketiga jenis penilaian: penilaian kata benda yang tidak dimodifikasi (seperti yang digunakan dalam Eksperimen 1), dan penilaian kata sifat yang dimodifikasi “gelap” dan “terang”. Penilaian ini awalnya diberi skor antara 0 dan 50 (terang ke gelap), yang kami ubah menjadi antara 0 dan 1 (terang ke gelap). Karena ada 42 kata benda dalam kumpulan data, total ada 126 frasa kata sifat–kata benda.
3.1.2 Penanaman
Bahasa Indonesia: Untuk embedding Word2Vec , kami menggunakan embedding pra-latihan yang dijelaskan dalam Eksperimen 1. Kami menggabungkan embedding kata sifat dan kata benda untuk setiap frasa ( d = 600). Untuk embedding BERT , kami menggunakan token CLS, yang bertindak sebagai representasi gabungan dari kata sifat dan kata benda, daripada menggabungkan embedding tingkat kata. Token CLS adalah token klasifikasi yang diperlukan di awal setiap kalimat yang dimasukkan ke BERT. Ini dipahami sebagai representasi tingkat kalimat dari input, yang dibuat dengan mempertimbangkan tugas klasifikasi (Devlin et al., 2018 ; Munikar, Shakya, & Shrestha, 2019 ). Karena ini merupakan representasi luas dari makna input multi-kata, kami menggunakan token CLS sebagai keseluruhan representasi kata sifat-kata benda dalam analisis kami. Untuk kondisi yang diminta secara kontekstual, kami memasukkan frasa seperti “kecerahan arang gelap” ke dalam BERT dan mengekstrak token CLS untuk keseluruhan frasa. Sebaliknya, untuk kondisi bebas konteks, kami hanya memasukkan frasa kata sifat-kata benda, misalnya, “arang gelap” dan mengekstrak token CLS. Ini berarti bahwa penyematan BERT kami selalu memiliki dimensionalitas yang sama (dasar: d = 768; besar: d = 1024). Tidak mungkin untuk merata-ratakan penyematan bebas konteks pada beberapa konteks kalimat (seperti dalam Eksperimen 1) karena banyak frasa kata sifat-kata benda tidak muncul dalam korpus Tolok Ukur Satu Miliar Kata. Akhirnya, kami kembali menggunakan skema pengodean one-hot untuk bertindak sebagai model dasar. Masukan untuk model ini terdiri dari satu unit untuk setiap frasa kata sifat-kata benda.
3.1.3 Model
Kami kembali menggunakan validasi silang 10 kali lipat untuk mengevaluasi model kami. Dalam Eksperimen 1, setiap lipatan pengujian berisi subset kata benda yang tidak dilatihkan pada model sehingga kami dapat menguji generalisasi pada kata benda baru ini. Dalam penyelidikan saat ini, kami malah tertarik pada seberapa akurat penyematan dapat memprediksi kecerahan kombinasi kata sifat-kata benda baru, setelah dilatih pada kata sifat dan kata benda yang sama dalam kombinasi yang berbeda. Dengan demikian, untuk setiap pemisahan pelatihan-pengujian, kami memastikan bahwa setidaknya satu versi dari setiap kata benda (kata benda gelap, kata benda terang, atau kata benda berat) muncul dalam set pelatihan. Ini memastikan bahwa kami tidak menguji pada kata benda yang sebelumnya tidak terlihat, melainkan pada kombinasi kata sifat-kata benda yang sebelumnya tidak terlihat (lihat Gambar 7 untuk contoh). Semua spesifikasi model lainnya sama dengan penyelidikan kata benda kami, dengan penyetelan hiperparameter untuk jumlah unit tersembunyi dan jumlah periode yang dilakukan secara khusus untuk set data kata sifat.
3.1.4 Evaluasi
Prosedur evaluasi kami serupa dengan Eksperimen 1. Kami kembali menginisialisasi 10 model berbeda dengan bobot awal acak untuk menghindari efek derau acak. Masing-masing dari 10 model dilatih dan diuji menurut skema validasi silang 10 kali lipat yang dijelaskan untuk Eksperimen 1 (lihat Materi Tambahan untuk deviasi standar kinerja di seluruh model). Kami memperoleh prediksi tunggal untuk setiap kombinasi kata sifat–kata benda dengan merata-ratakan prediksi dari 10 model. Kami mengevaluasi kinerja penyematan yang berbeda, dipisahkan berdasarkan kata sifat, menggunakan MSE dan R 2 . Dengan demikian, metrik kami mengindeks kemampuan untuk memprediksi kecerahan di seluruh kata benda saat dipasangkan dengan kata sifat yang sama. Selain itu, kami menjalankan uji statistik pada perbandingan minat kami, yang diuraikan di bawah ini. Kami menggunakan uji peringkat bertanda Wilcoxon, yang merupakan uji nonparametrik sampel berpasangan, yang membandingkan kesalahan kuadrat untuk frasa kata sifat–kata benda “terang” dan “gelap”.
- Word2Vec versus BERT bebas konteks
- “Kecerahan” didorong secara kontekstual BERT versus “warna” didorong secara kontekstual BERT
- BERT bebas konteks versus BERT yang diminta secara kontekstual
Penyematan dengan kinerja terbaik dari perbandingan perintah (yaitu, perintah kecerahan vs. perintah warna) dipilih untuk perbandingan BERT bebas konteks dan perintah kontekstual di atas. Kami juga menyajikan evaluasi kualitatif tentang seberapa baik penyematan menangkap efek nonaditif dari kecerahan kata sifat pada kecerahan kata benda.
3.2 Hasil
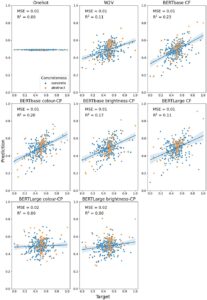
Kami mengevaluasi investigasi kata sifat dengan cara yang sama dengan investigasi kata benda; namun, kami melaporkan kinerja model secara terpisah berdasarkan kata sifat (lihat Gambar 8 untuk ikhtisar).
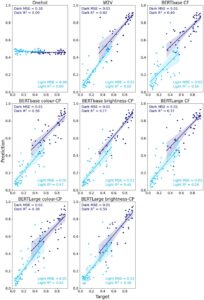
Secara umum, semua embedding dapat memprediksi kecerahan frasa kata sifat-kata benda baru dengan baik (lihat Tabel 4 ). Kami menemukan bahwa embedding Word2Vec memiliki kinerja terbaik secara keseluruhan (Gelap: MSE = 0,01, R 2 = 0,62; Terang: MSE = 0,01, R 2 = 0,65).
| MSE | R 2 | |
|---|---|---|
| Satu Panas | ||
| Gelap | 0.10 | .00 |
| Lampu | 0,08 | .00 |
| Kata2Vec | ||
| Gelap | 0,01 | .62 |
| Lampu | 0,01 | .65 |
| BERTbase bebas konteks | ||
| Gelap | 0,01 | .60 |
| Lampu | 0,02 | .16 |
| BERTbase diminta berdasarkan konteks warna | ||
| Gelap | 0,01 | .56 |
| Lampu | 0,01 | .47 |
| BERTbase kecerahan diminta secara kontekstual | ||
| Gelap | 0,01 | .77 |
| Lampu | 0,01 | .44 |
| BERTLarge bebas konteks | ||
| Gelap | 0,01 | .57 |
| Lampu | 0,02 | .24 |
| BERTLarge diminta berdasarkan konteks warna | ||
| Gelap | 0,02 | .38 |
| Lampu | 0,01 | .42 |
| BERTLarge kecerahan-diminta secara kontekstual | ||
| Gelap | 0,01 | .55 |
| Lampu | 0,02 | .36 |
Bertentangan dengan prediksi kami, dalam analisis penempatan dekontekstualisasi kami, kami menemukan bahwa penempatan Word2Vec secara signifikan lebih baik dalam prediksi persepsi daripada penempatan BERT bebas konteks (dasar: p = .0001; besar: p = .0007). Untuk perbandingan efektivitas perintah, kami tidak menemukan perbedaan signifikan antara perintah “warna” dan “kecerahan” (dasar: p = .17; besar: p = .68). Dengan demikian, untuk analisis kontekstual, kami memilih perintah “kecerahan” karena umumnya memiliki nilai R 2 yang lebih tinggi . Kami menemukan bahwa penempatan BERTbase yang diminta secara kontekstual berkinerja secara signifikan lebih baik daripada penempatan bebas konteks ( p = .02). Namun, tidak ada perbedaan signifikan antara keduanya untuk penempatan BERTLarge ( p = .84).
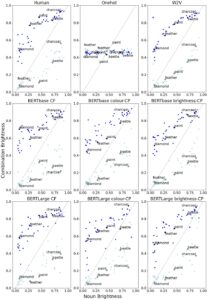
Salah satu aspek utama dari kumpulan data S&T-S kata sifat–kata benda adalah efek nonaditif dari kata sifat pada peringkat kecerahan. “Modulasi fleksibel” ini ditunjukkan di panel kiri atas Gambar 9 yang memetakan peringkat manusia untuk kecerahan kata sifat–kata benda (sumbu y) sebagai fungsi kecerahan kata benda (sumbu x). Kata sifat sangat memodulasi kecerahan kata benda yang berada di tengah spektrum (misalnya, “cat”), sementara kata sifat memiliki efek yang lebih kecil pada kata benda dengan nilai kecerahan yang lebih ekstrem (misalnya, “arang”). Kita dapat melihat pola yang sama (kelengkungan titik data) untuk penyematan kata.
3.3 Diskusi
Secara keseluruhan, kami mengamati kinerja yang baik untuk prediksi persepsi pada kombinasi kata sifat-kata benda yang tidak terlihat untuk penempatan kata yang telah dilatih sebelumnya, tetapi tidak untuk garis dasar one-hot. Kami juga menemukan bahwa penempatan meniru “modulasi fleksibel” nonaditif yang terlihat dari data manusia, yang menunjukkan bahwa LLM dapat menangkap aspek kompleks dari kombinasi konseptual. Namun, di sini kami menemukan bahwa penempatan Word2Vec mengungguli penempatan BERT bebas konteks, berbeda dengan temuan Eksperimen 1 kami. Mungkin ini karena kata sifat dan kata benda direpresentasikan secara terpisah dalam masukan Word2Vec kami, karena ini merupakan gabungan dari dua penempatan konstituen, sedangkan penempatan BERT bebas konteks kami adalah representasi tunggal dan campuran dari kedua kata tersebut. Kami menemukan bahwa penambahan konteks memiliki dampak terbatas pada kinerja persepsi, dengan bukti sederhana bahwa menyertakan perintah terhadap fitur dapat mengungkap informasi terkait fitur tambahan.
4 Diskusi umum
Dalam studi ini, kami menyelidiki kemampuan embedding dari Distributional Semantic Models dan Large Language Models untuk merepresentasikan informasi perseptual, membandingkan embedding dengan berbagai tingkat kendala kontekstual. Dalam Eksperimen 1, kami membandingkan embedding kata yang dikontekstualisasikan dan didekontekstualisasikan pada kinerja mereka pada prediksi perseptual untuk kecerahan dan bentuk yang terkait dengan kata benda. Secara umum, kami menemukan prediksi bentuk yang sangat baik dan prediksi kecerahan yang lebih sederhana, yang menunjukkan bahwa model bahasa menangkap beberapa aspek persepsi makna melalui paparan informasi linguistik saja. Bentuk umumnya diprediksi lebih baik daripada kecerahan, mereplikasi temuan sebelumnya (Chersoni et al., 2021 ; Turton et al., 2020, 2021 ). Dalam investigasi baru kami tentang konteks, kami tidak menemukan keuntungan untuk mengontekstualisasikan embedding dengan fitur perseptual yang diinginkan (misalnya, “kecerahan arang”). Faktanya, ini paling sering menyebabkan kinerja yang lebih buruk. Untuk Eksperimen 2, kami menyelidiki apakah penempatan kata secara fleksibel mewakili modulasi sifat persepsi yang terjadi saat kata benda dimodifikasi oleh kata sifat (misalnya, “arang gelap”). Karya ini memperluas temuan sebelumnya untuk fokus pada bagaimana fitur konseptual dari berbagai masukan berinteraksi dalam ekspresi multikata. Secara keseluruhan, penempatan berhasil memprediksi sifat kombinasi kata sifat-kata benda baru, dan kami menemukan bukti terbatas untuk efektivitas permintaan kontekstual pada prediksi fitur persepsi. Kami juga menemukan bahwa efek nonaditif kata sifat pada kecerahan kata benda terwakili dalam penempatan, yang meniru karakteristik kualitatif utama dari kumpulan data manusia (Solomon & Thompson-Schill, 2020 ). Hasil ini memiliki implikasi untuk memahami sejauh mana aspek pengalaman persepsi yang diwujudkan dikodekan dalam statistik bahasa.
Kami menemukan prediksi yang umumnya baik dari fitur persepsi dari berbagai set penempatan kata yang telah dilatih sebelumnya yang diuji. Ini bahkan berlaku untuk prediksi kecerahan, yang merupakan fitur yang menurut penelitian sebelumnya tidak dapat diprediksi dengan baik (Chersoni et al., 2021 ; Turton et al., 2021 ; Utsumi, 2020 ). Satu hal yang perlu diperhatikan adalah perbedaan kinerja saat memprediksi kecerahan untuk dua set data. Hasil kami menunjukkan bahwa kinerja mungkin sangat bergantung pada set konsep yang digunakan untuk menguji prediksi. Penelitian sebelumnya sangat bergantung pada set data Binder, yang mencakup berbagai macam konsep. Kami menemukan kinerja yang lebih baik untuk prediksi kecerahan saat kami menggunakan set data S&T-S, yang berisi set konsep yang lebih disesuaikan yang kecerahannya merupakan fitur yang relevan. Solomon dan Thompson-Schill ( 2020 ) menyusun set data mereka untuk menyertakan konsep yang mewakili spektrum nilai kecerahan. Kami menemukan bahwa hal ini menghasilkan kinerja prediksi yang lebih baik dibandingkan dengan set data Binder, yang menyertakan banyak konsep yang kecerahannya bukan merupakan fitur yang menonjol. Dengan demikian, mungkin penting untuk menggunakan data yang mencakup spektrum peringkat fitur persepsi saat menilai kemampuan representasional penyematan kata.
Selain itu, temuan kami menunjukkan bahwa bentuk lebih kuat terwakili dalam penanaman kata daripada kecerahan suatu konsep, mereplikasi hasil sebelumnya (Chersoni et al., 2021 ; Turton et al., 2020, 2021 ). Ini bisa jadi sebagian karena tingkat bentuk suatu konsep sangat terkait dengan tingkat konkret atau abstraknya konsep tersebut. Konsep yang lebih abstrak (misalnya, “pemerintah”) secara andal memiliki peringkat yang lebih rendah dibandingkan dengan konsep yang lebih konkret (misalnya, “meja”; lihat Gambar 6 ). Hubungan ini tidak berlaku untuk kecerahan, di mana beberapa konsep abstrak (misalnya, “musim panas”) dapat dinilai tinggi dan banyak konsep konkret bersifat netral. Dengan demikian, ada kemungkinan bahwa prediksi bentuk dibantu oleh korelasi fitur ini dengan konkret, yang sangat menonjol baik secara psikologis maupun linguistik (Barsalou, Dutriaux, & Scheepers, 2018 ; Paivio, 1990 ). Akan tetapi, kinerja yang lebih baik tampaknya tidak hanya berasal dari efek bootstrapping dari informasi konkret, karena kami mengamati kinerja prediksi yang lebih baik untuk bentuk bahkan ketika hanya kata benda konkret yang disertakan.
Bahasa Indonesia: Dalam hal perbedaan antara word embeddings, kami menemukan bahwa embedding BERT bebas konteks, yang dirata-ratakan di banyak konteks, umumnya mengungguli embedding Word2Vec dalam memprediksi peringkat persepsi dalam Eksperimen 1. Ini mereplikasi temuan sebelumnya dan menunjukkan bahwa menyelidiki word embeddings di beberapa konteks dapat menghasilkan representasi yang lebih kuat daripada embedding statis (Bommasani et al., 2020 ; Turton et al., 2021 ; Vulić et al., 2020 ). Dari investigasi baru kami dengan penambahan prompt kontekstual, kami menemukan bahwa embedding BERT yang diminta secara kontekstual tidak menghasilkan kinerja yang lebih baik daripada embedding BERT bebas konteks kami. Dalam beberapa keadaan, kami benar-benar menemukan kinerja yang lebih buruk. Ini tidak sejalan dengan apa yang kami amati pada manusia, di mana konteks memiliki efek yang kuat dalam membentuk bagaimana konsep tertentu diambil dan ditafsirkan (lihat Yee & Thompson-Schill, 2016 untuk tinjauan komprehensif). Dalam satu contoh yang tepat, Bermeitinger, Wentura, dan Frings ( 2011 ) memberi peserta tugas yang menarik perhatian pada bentuk konsep, diselingi dengan tugas priming semantik. Hal ini menghasilkan priming yang lebih besar untuk konsep-konsep di mana bentuk merupakan fitur yang relevan, dibandingkan dengan konsep-konsep yang kurang relevan dengan bentuk. Jenis fasilitasi semantik yang berdasarkan pada interaksi antara konteks dan fitur-fitur suatu konsep ini adalah temuan yang kuat dengan menggunakan metode perilaku dan neuroimaging (Hoenig, Sim, Bochev, Herrnberger, & Kiefer, 2008 ; Hoffman, McClelland, Ralph, & M., 2018 ; Kuhnke, Kiefer, & Hartwigsen, 2020 ; Tabossi & Johnson-Laird, 1980 ; Van Dam, Rueschemeyer, Lindemann, & Bekkering, 2010 ; van Dam et al., 2012 ; Yee, Ahmed, & Thompson-Schill, 2012 ). Temuan-temuan seperti ini mengindikasikan bahwa fitur-fitur persepsi yang diaktifkan manusia saat memproses suatu konsep sangat dipengaruhi oleh konteks terkini. Namun, dorongan kontekstual tampaknya tidak membentuk ekspresi informasi khusus-fitur dalam LLM berbasis Transformer dengan cara yang sama.
Hasil kami menunjukkan bahwa prompt perseptual tertentu mungkin tidak merekayasa representasi yang lebih mencerminkan properti tertentu dan bahwa penyematan bebas konteks (teragregasi atas banyak konteks) lebih efektif. Ini mungkin salah satu cara di mana representasi semantik yang diekstraksi dari model bahasa berbeda dari pemahaman kita tentang representasi semantik di otak manusia. Pekerjaan masa depan yang mempertimbangkan berbagai fitur dan prompt yang lebih luas akan memberikan wawasan yang lebih besar ke dalam cara di mana konteks memengaruhi representasi fitur semantik yang berbeda dalam penyematan kata. Mungkin juga bahwa LLM yang lebih baru dan lebih besar lebih mampu menangkap konteks daripada BERT, yang tidak begitu cocok untuk jenis prompt ini. Dengan demikian, eksplorasi masa depan tentang bagaimana arsitektur model yang berbeda menangani tugas ini mungkin juga menarik. Antara dua versi model BERT, menarik untuk dicatat bahwa BERTLarge tidak secara konsisten mengungguli penyematan BERTbase. BERTLarge adalah model yang jauh lebih besar, dengan lebih dari tiga kali lebih banyak parameter daripada BERTbase, dan dilaporkan mengungguli BERTbase pada berbagai tugas pemrosesan bahasa (Devlin et al., 2018 ). Akan tetapi, yang lain berpendapat bahwa model BERT kurang terlatih secara signifikan (Liu et al., 2019 ) dan mungkin saja dengan pelatihan yang lebih besar, BERTLarge akan secara konsisten menyalip model yang lebih kecil dalam perbandingan persepsi kami.
Dalam Eksperimen 2, kami mengeksplorasi kemampuan untuk memprediksi nilai fitur persepsi dari penempatan kata untuk frasa kata sifat-kata benda baru, setelah memiliki pengalaman dengan masing-masing konstituennya. Kami menemukan bahwa penempatan Word2Vec secara umum mengungguli penempatan BERT bebas konteks. Di sini, penempatan Word2Vec kami merupakan gabungan dari penempatan kata sifat dan kata benda, sementara untuk penempatan BERT bebas konteks kami, kami mengambil token CLS untuk mewakili seluruh frasa kata sifat-kata benda. Ada kemungkinan bahwa memiliki representasi kata sifat dan kata benda yang berbeda menghasilkan kinerja yang lebih baik untuk penempatan Word2Vec dalam tugas ini. Meskipun demikian, penempatan BERT bekerja dengan baik pada tugas ini, yang menunjukkan bahwa representasi tingkat frasa terintegrasi (yaitu, token CLS) juga membawa informasi persepsi. Kami juga menemukan dampak terbatas dari permintaan kontekstual pada prediksi, karena penempatan BERTbase yang diminta secara kontekstual bekerja secara signifikan lebih baik daripada penempatan BERTbase bebas konteks kami. Namun, hubungan ini tidak berlaku untuk penyematan BERTLarge. Kami menganggap ini sebagai bukti sederhana bahwa penyediaan perintah kontekstual dapat mengungkap informasi terkait fitur lebih lanjut. Kami juga menemukan bukti sifat nonaditif dari kecerahan kata sifat–kata benda yang tercermin dalam penyematan. Karakteristik ini mengacu pada cara variabel di mana modifikasi dengan kata sifat memengaruhi peringkat kecerahan kata benda (Solomon & Thompson-Schill, 2020 ). Misalnya, konsep kecerahan sedang, seperti “cat,” memiliki variasi yang lebih besar dalam peringkat kecerahan di seluruh kombinasi kata sifat, daripada konsep kecerahan ekstrem, seperti “arang.” Temuan ini menunjukkan bahwa jenis modulasi fleksibel yang ditemukan dalam cara manusia merepresentasikan konsep juga tercermin dalam penyematan kata.
Secara keseluruhan, studi kami konvergen dengan investigasi sebelumnya dalam menyarankan bahwa tingkat informasi persepsi yang mengejutkan dapat ditransfer melalui konten linguistik saja. Utsumi ( 2020 ) menyarankan bahwa bahasa adalah realisasi pengalaman di dunia nyata, dengan menyatakan bahwa jenis statistik yang digunakan oleh model bahasa secara implisit melibatkan pengetahuan konseptual dari pengalaman langsung. Temuan kami mendukung pandangan ini, yang paling sesuai dengan penjelasan kognisi yang terpadu, di mana pemrosesan mengintegrasikan elemen yang diwujudkan dan simbolik (Andrews et al., 2014 ; 2009 ; Louwerse, 2011, 2018 ). Penjelasan seperti Hipotesis Interdependensi Simbol menekankan penggunaan pemetaan simbol-ke-simbol, serta pemetaan simbol-ke-dunia (Louwerse, 2011 ). Pekerjaan saat ini menambah badan literatur yang menunjukkan bahwa representasi semantik yang dipelajari menggunakan metode distribusional sering kali selaras dengan yang didasarkan pada laporan pengalaman persepsi (Chersoni et al., 2021 ; Lucy & Gauthier, 2017 ; Sommerauer & Fokkens, 2018 ; Utsumi, 2020 ). Bukti tambahan untuk sistem representasi ganda semacam ini ditinjau oleh Bi ( 2021 ), yang menyoroti studi perilaku dan neuroimaging pengetahuan warna pada mereka yang memiliki pengalaman visual dan mereka yang tidak (yaitu, peserta tunanetra sejak lahir). Bukti dari decoding saraf menunjukkan sistem pengetahuan warna yang berasal dari bahasa nonsensorik pada kedua kelompok peserta, dengan representasi yang berasal dari sensorik tambahan yang ada bagi mereka yang memiliki pengalaman visual. Ini menunjukkan bahwa manusia dapat dan memang memperoleh pengetahuan persepsi melalui bahasa sampai tingkat tertentu. Bukti ini lebih sejalan dengan pendekatan perwujudan lemah, seperti yang diajukan oleh Dove ( 2014 ), yang berpendapat bahwa bahasa itu sendiri berwujud dan berinteraksi dengan sistem berwujud lainnya (yaitu, persepsi dan tindakan). Penjelasan relevan lainnya adalah teori Simulasi Linguistik dan Situasional (Barsalou et al., 2008 ; Santos, Chaigneau, Simmons, & Barsalou, 2011 ), yang mengusulkan bahwa pemrosesan leksikal-semantik melibatkan aktivasi awal informasi linguistik dan didukung oleh proses berwujud selanjutnya yang mensimulasikan pengalaman sensorimotor yang relevan.
Kemungkinan arah untuk penelitian di masa depan termasuk menyelidiki bagaimana berbagai jenis fitur semantik dikodekan dalam bahasa untuk konsep konkret dan abstrak. Secara khusus berfokus pada makna dalam LLM, Piantadosi dan Hill ( 2022 ) berpendapat bahwa makna tidak hanya lahir dari landasan, tetapi lebih pada bagaimana konsep saling berhubungan. Mereka mengklaim bahwa pemetaan interaksi antara konsep ini umum bagi manusia dan mesin. Menjelajahi mekanisme di balik bagaimana LLM memperoleh kemampuan representasional semacam ini akan menjadi arah yang menarik untuk pekerjaan di masa depan. Arah lain yang mungkin adalah menyelidiki sejauh mana sifat persepsi interaksi direpresentasikan dalam model. Sementara kita telah mengeksplorasi sifat interaksi kata sifat dan kata benda, ada banyak interaksi yang terlibat dalam segudang kombinasi konseptual, seperti senyawa kata benda-kata benda, yang memerlukan penyelidikan lebih lanjut (Coutanche et al., 2019 ). Selain itu, pekerjaan yang mempertimbangkan implementasi yang berbeda dalam ekstraksi dan pengujian penanaman kata akan mengatasi salah satu keterbatasan dari pekerjaan saat ini. Misalnya, ini dapat mencakup berbagai metode untuk mengekstraksi kata yang disematkan, atau penggunaan perintah yang lebih terperinci saat mengontekstualisasikan ke fitur tertentu. Penelitian lebih lanjut di bidang ini akan memungkinkan analisis yang lebih baik tentang generalisasi temuan saat ini.
Sebagai kesimpulan, pekerjaan kami saat ini melengkapi literatur terkini yang menyelidiki hubungan antara penempatan kata dan penilaian semantik manusia. Kami mereplikasi hasil sebelumnya yang menunjukkan kinerja yang umumnya baik untuk prediksi beberapa fitur persepsi, yaitu bentuk, sementara kecerahan kurang terwakili dengan baik. Dalam kontribusi baru kami, kami menemukan bahwa penambahan perintah kontekstual memiliki peningkatan terbatas pada kemampuan representasi penempatan kata untuk prediksi persepsi. Selain itu, penempatan kata mencerminkan beberapa modulasi fleksibel fitur persepsi yang terjadi dalam komposisi semantik, khususnya, modifikasi dengan kata sifat. Penelitian di masa mendatang dapat difokuskan pada pembuatan perintah konteks yang lebih spesifik dan memperluasnya ke fitur lain. Ini dapat mengungkapkan wawasan lebih jauh tentang bagaimana konteks linguistik memengaruhi representasi semantik yang direkayasa.

