
Abstrak
Perangkap pembelajaran aturan sederhana terjadi ketika orang menunjukkan pembelajaran kategori yang kurang optimal karena eksplorasi lingkungan belajar yang tidak memadai. Dengan menggabungkan metode eksperimental dan pemodelan komputasional, studi terkini menyelidiki dampak dari dua faktor utama yang diyakini memainkan peran penting dalam pengembangan perangkap pembelajaran aturan sederhana: pengalaman belajar awal dan perhatian selektif. Hasil kami menunjukkan bahwa, dalam lingkungan belajar di mana pemetaan kategori sebenarnya ditentukan oleh konjungsi dua dimensi prediktif, kemungkinan jatuh ke dalam perangkap pembelajaran satu dimensi meningkat ketika pengalaman belajar awal melibatkan kerugian besar yang dapat diprediksi dari satu dimensi fitur. Selain itu, dengan menggunakan pengukuran bias perhatian berbasis model, kami mengamati bahwa pengalaman awal memengaruhi pembentukan perangkap dengan mempersempit distribusi perhatian ke fitur contoh. Temuan ini memberikan bukti empiris langsung pertama tentang bagaimana pengalaman belajar awal membentuk pembentukan perangkap pembelajaran aturan sederhana, serta pemahaman yang lebih terperinci tentang peran perhatian selektif dan interaksinya dengan pengalaman belajar awal dalam pembentukan perangkap.
1 Pendahuluan
Bahasa Indonesia: Dari keputusan sehari-hari seperti berbelanja kebutuhan pokok hingga investasi keuangan yang signifikan, kita sering kali mengandalkan keyakinan yang diperoleh melalui pengalaman sebelumnya untuk memandu pilihan kita. Misalnya, saat terlibat dalam perdagangan saham, kita mungkin merenungkan pengalaman masa lalu kita dengan jenis saham tertentu untuk menentukan apakah kita ingin membelinya lagi. Terlepas dari keinginan kita untuk mengetahui segala sesuatu di mana-mana sekaligus, para pengambil keputusan pasti dibatasi oleh dilema eksplorasi-eksploitasi (Sutton & Barto, 2018 ) saat membuat keputusan dari pengalaman (Hertwig, Barron, Weber, & Erev, 2004 ; Hills, 2006 ; Mehlhorn et al., 2015 ). Untuk memaksimalkan imbalan keseluruhan, kita perlu menyeimbangkan potensi keuntungan dari mempelajari pengetahuan baru dengan manfaat dari penggunaan pengetahuan yang ada.
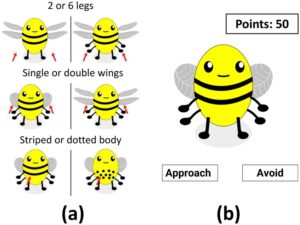
Perhatian selektif memainkan peran penting dalam menangani dilema eksplorasi-eksploitasi (Niv et al., 2015 ). Hal ini memungkinkan para pengambil keputusan untuk fokus pada informasi yang relevan sambil menyaring rincian yang tidak relevan (Broadbent, 2013 ). Meskipun demikian, mekanisme yang tampaknya efisien ini terkadang dapat menghasilkan keputusan yang suboptimal. Rich dan Gureckis ( 2018 ) mendokumentasikan perangkap pembelajaran aturan sederhana dalam lingkungan di mana stimulus (misalnya, lebah kartun) terdiri dari beberapa dimensi fitur bernilai biner (lihat contoh pada Gambar 1 ). Konjungsi fitur pada dua dimensi ini menentukan kategori stimulus (yaitu, lebah yang aman atau berbahaya pada Gambar 2a ), dan kategori yang berbeda dikaitkan dengan struktur imbalan yang berbeda (yaitu, mendekati lebah yang aman menghasilkan pengembalian positif, sementara mendekati lebah yang berbahaya menghasilkan kerugian; menghindari salah satunya menghasilkan pengembalian nol).
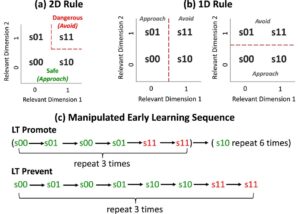
Ketika keanggotaan kategori stimulus diinformasikan setelah setiap respons (yaitu, pembelajaran kategori umpan balik penuh), peserta dengan mudah mempelajari struktur kategori konjungtif. Namun, ketika umpan balik korektif tersedia hanya setelah stimulus didekati (yaitu, umpan balik kontingen), banyak pembelajar akhirnya jatuh ke dalam perangkap aturan sederhana; mereka mengklasifikasikan stimulus berdasarkan satu dimensi prediktif (aturan 1D, lihat Gambar 2b ) daripada kedua dimensi (aturan 2D, lihat Gambar 2a ). Penggunaan aturan 1D menghasilkan pengembalian total yang kurang optimal karena pembelajar kehilangan kesempatan untuk mengeksplorasi opsi yang dapat menghasilkan imbalan.
Di luar laboratorium, umpan balik sering kali bergantung pada keputusan—hanya tersedia saat opsi keputusan dipilih tetapi tidak saat dihindari (Denrell, 2005 ; Elwin, Juslin, Olsson, & Enkvist, 2007 ). Oleh karena itu, perangkap aturan sederhana telah terbukti muncul dalam berbagai lingkungan, seperti pengembangan stereotip negatif terhadap kelompok luar (Denrell, 2005 ) dan dalam psikopatologi seperti depresi, keduanya dicirikan oleh penghindaran pengalaman yang berpotensi memberi penghargaan (Teodorescu & Erev, 2014 ). Selain itu, perangkap tersebut tetap ada bahkan ketika pembelajar memiliki banyak kesempatan untuk mengeksplorasi pilihan-pilihan yang akan membatalkan aturan satu dimensi, yang mengarah pada pengurangan substansial dalam penghargaan yang diperoleh (Lee, Li, Lee, & Hayes, 2024 ; Liu, Newell, Lee, & Hayes, 2024; Li, Gureckis, & Hayes, 2021 ; Rich & Gureckis, 2018 ). Selain itu, pembelajar yang jatuh ke dalam perangkap pembelajaran aturan sederhana juga sering kali tidak menyadari perubahan dinamis dalam struktur penghargaan (Blanco, Turner, & Sloutsky, 2023 ; Lee et al., 2024 ). Memahami proses yang mendorong pembentukan perangkap dapat membantu kita mengidentifikasi solusi untuk biaya negatif yang ditimbulkannya.
Rich dan Gureckis ( 2018 ) menguraikan penjelasan deskriptif tentang bagaimana perangkap pembelajaran aturan sederhana dapat muncul. Menurut penjelasan mereka, hasil positif awal mengikuti pendekatan subset stimulus dengan fitur menonjol dapat mengarah pada keyakinan yang salah bahwa nilai pada dimensi tunggal ini dapat memprediksi semua hasil pilihan. Preferensi untuk aturan sederhana daripada aturan kompleks ini dapat mencerminkan bias induktif umum (misalnya, Chater & Vitányi, 2003 ; Feldman, 2016 ; Pothos & Close, 2008 ). Misalnya, mari kita asumsikan bahwa lebah yang “aman” diidentifikasi oleh aturan yang melibatkan nilai pada dua dimensi: pola tubuh dan jumlah kaki. Jika pembelajar menerima umpan balik positif dari mendekati lebah dengan fitur tubuh prediktif di awal pembelajaran mereka, mereka mungkin secara keliru percaya bahwa pola tubuh cukup untuk memprediksi hasil untuk semua jenis lebah. Hal ini dapat mengakibatkan peningkatan perhatian pada fitur tubuh dan penurunan perhatian pada fitur prediktif lainnya (misalnya, jumlah kaki dalam contoh ini). Akibatnya, peserta didik terjebak dalam perangkap pembelajaran aturan sederhana dengan menghindari stimulus tanpa fitur tubuh yang menonjol pada percobaan berikutnya, meskipun beberapa di antaranya bermanfaat.
1.1 Menguji deskripsi perangkap pembelajaran
Dengan manipulasi empiris baru dan analisis berbasis model baru, penelitian ini bertujuan untuk menguji asumsi utama dari penjelasan Rich dan Gureckis ( 2018 ) mengenai: (1) peran pengalaman awal dalam pengembangan perangkap pembelajaran aturan sederhana, dan (2) bagaimana pengalaman tersebut berinteraksi dengan perhatian selektif terhadap fitur stimulus dalam pembentukan perangkap.
Untuk tujuan ini, kami melakukan eksperimen dengan tugas “memanen madu” yang mirip dengan yang digunakan oleh Rich dan Gureckis ( 2018 ), di mana kategori lebah diprediksi oleh konjungsi dua fitur yang relevan. Manipulasi empiris utama untuk menguji asumsi pertama adalah urutan pembelajaran awal yang menentukan kapan peserta pertama kali menghadapi stimulus yang menghasilkan kerugian besar. Kami berhipotesis bahwa ketika lebah berbahaya muncul sebelum peserta didik mengalami semua jenis lebah aman (yaitu, kondisi Learning Trap [LT] Promote, lihat baris atas pada Gambar 2c ), itu akan membiaskan perhatian peserta didik terhadap satu dimensi dan menghasilkan kemungkinan yang lebih tinggi untuk jatuh ke dalam perangkap pembelajaran aturan sederhana. Sebaliknya, ketika semua jenis konjungsi “aman” muncul sebelum kerugian besar (kondisi LT Prevent, lihat baris bawah pada Gambar 2c ), ini dapat mengurangi prevalensi pengguna aturan 1D karena peserta didik lebih mungkin menerima umpan balik kategori korektif yang membatalkan aturan satu dimensi.
Desain urutan promote LT kami terinspirasi, sebagian, oleh karya sebelumnya yang menunjukkan bahwa penyajian “terblokir” dari contoh-contoh dari kategori yang kontras mempromosikan pembelajaran fitur-fitur yang membedakan kategori tersebut (misalnya, Carvalho & Goldstone, 2017, 2022 ). Dalam kasus kami, urutan promote LT dimaksudkan untuk menarik perhatian ke satu dimensi fitur yang membedakan lebah aman dari lebah berbahaya. Dalam nada yang sama, penyajian contoh-contoh yang diblokir yang sesuai dengan aturan logis yang sama (misalnya, aturan dimensi 1D dalam urutan promote LT kami) dapat mempromosikan pembelajaran aturan (Mathy & Feldman, 2009 ). Sebaliknya, urutan Prevent LT kami secara eksplisit menghindari pemblokiran stimulus berdasarkan satu dimensi. Uji coba awal dalam urutan ini dimaksudkan untuk menunjukkan bahwa fitur-fitur lebah aman dapat bervariasi di dua dimensi.
Prediksi kami tentang pengalaman belajar awal berlaku terutama untuk lingkungan belajar dengan umpan balik kontingen, di mana umpan balik kategori korektif hanya muncul setelah mendekati keputusan. Jika umpan balik diberikan pada setiap percobaan pembelajaran (yaitu, umpan balik penuh), perangkap pembelajaran cenderung tidak terbentuk. Ini karena umpan balik penuh dapat memberikan diskonfirmasi langsung dari aturan 1D sederhana (Lee et al., 2024 ; Li et al., 2021 ; Rich & Gureckis, 2018 ), yang akan membantu orang keluar dari perangkap pembelajaran aturan sederhana, terlepas dari urutan pembelajaran awal. Kami melakukan eksperimen dengan umpan balik penuh dan kontingen untuk menguji prediksi ini.
Asumsi kunci kedua dari uraian Rich dan Gureckis ( 2018 ) adalah bahwa pengalaman belajar awal dapat mengubah distribusi perhatian di antara dimensi-dimensi fitur selama pembelajaran kategori. Bukti awal telah ditunjukkan untuk mendukung asumsi ini. Dalam lingkungan pembelajaran kategori yang dinamis di mana terjadi peralihan dimensi fitur prediktif yang tidak diumumkan, Blanco et al. ( 2023 ) menemukan bahwa anak-anak yang mendistribusikan perhatian di antara fitur-fitur stimulus secara luas di awal pembelajaran cenderung tidak melewatkan peralihan penting ini dan jatuh ke dalam perangkap pembelajaran, dibandingkan dengan orang dewasa yang distribusi perhatian awalnya jauh lebih sempit selama pembelajaran.
Pekerjaan saat ini melampaui Blanco et al. ( 2023 ) dengan menguji interaksi antara pengalaman awal dan perhatian selektif dengan manipulasi eksplisit dari rangkaian pembelajaran awal. Selain itu, berdasarkan pekerjaan pemodelan Rich dan Gureckis ( 2018 ), kami memperoleh pengukuran berbasis model untuk menilai perubahan dalam distribusi perhatian dengan pengalaman awal yang dimanipulasi. Kami memperkirakan bahwa kondisi LT Promote kami akan memperkuat bias perhatian terhadap satu fitur relevan, sementara kondisi LT Prevent akan mengurangi bias ini.
Data yang dikumpulkan untuk semua eksperimen tersedia di Open Science Framework di: https://osf.io/pbf8y/ . Semua eksperimen dilakukan berdasarkan etika penelitian manusia #3333 yang disetujui oleh dewan peninjau institusional University of New South Wales.
2 Metode
2.1 Peserta
Untuk masing-masing dari enam kondisi (tiga rangkaian pembelajaran awal dengan umpan balik penuh atau bersyarat), kami bermaksud merekrut 751 peserta . Semua peserta direkrut melalui platform daring Prolific, dengan kriteria inklusi (1) fasih berbahasa Inggris, (2) berusia antara 18 dan 80 tahun, dan (3) telah menyelesaikan setidaknya 10 tugas Prolific dengan tingkat persetujuan minimal 90% atau lebih tinggi. Persetujuan yang diinformasikan diperoleh untuk setiap peserta. Mereka dibayar dengan tarif dasar £2/15 menit ditambah bonus berbasis kinerja mulai dari £0 hingga £1,34. Jumlah bonus ditentukan oleh poin yang dikumpulkan peserta selama percobaan. Setiap poin bernilai £0,01.
Tidak ada peserta yang dikecualikan dari analisis data. Secara keseluruhan, dengan umpan balik lengkap, kami memiliki 75 peserta dalam kondisi awal (26 wanita, 48 pria, 1 nonbiner; usia: M = 35,72, SD = 12,38), 80 dalam kondisi LT Prevent (35 wanita, 45 pria; usia: M = 38,73, SD = 13,19), dan 75 dalam kondisi LT Promote (26 wanita, 45 pria, dan 4 nonbiner; usia: M = 35,72, SD = 11,82). Dengan umpan balik bersyarat, kami memiliki 75 peserta dalam kondisi dasar (26 wanita, 48 pria, 1 nonbiner; usia: M = 35,72, SD = 12,38), 76 dalam kondisi Pencegahan LT (24 wanita, 51 pria, 1 nonbiner; usia: M = 35,11, SD = 13,23), dan 75 dalam kondisi Promosi LT (24 wanita, 49 pria, 2 nonbiner; usia: M = 37,32, SD = 12,80).
2.2 Bahan dan Prosedur
Kombinasi faktorial dari tiga dimensi fitur lebah bernilai biner (Gbr. 1a ), termasuk jumlah kaki (dua vs. enam), jumlah pasangan sayap (tunggal vs. ganda), dan pola tubuh (bergaris vs. putus-putus), menghasilkan delapan stimulus unik. Pada awal percobaan, dua dari tiga dimensi ini secara acak ditetapkan sebagai relevan untuk memprediksi keanggotaan kategori dengan dimensi ketiga tidak relevan untuk prediksi. Untuk setiap dimensi yang relevan, satu nilai fitur secara acak ditetapkan sebagai fitur yang berpotensi berbahaya (dilambangkan dengan 1), dan nilai fitur lainnya ditetapkan sebagai fitur yang aman (dilambangkan dengan 0).
Keanggotaan kategori lebah ditentukan oleh konjungsi nilai fitur pada dua dimensi yang relevan (Gbr. 2a ). Stimulus dengan setidaknya satu fitur aman tergolong dalam kategori aman (yaitu, s00, s01, dan s10). Stimulus dengan kedua fitur yang berpotensi berbahaya (s11) tergolong dalam kategori berbahaya. Misalnya, jika dua fitur yang berpotensi berbahaya adalah “dua kaki” dan “tubuh bertitik” (dalam hal ini, dimensi yang relevan adalah jumlah kaki dan pola tubuh, dimensi yang tidak relevan adalah jumlah sayap), maka lebah dengan enam kaki dan tubuh bergaris (s00), lebah dengan enam kaki dan tubuh bertitik (s01), dan lebah dengan dua kaki dan tubuh bergaris (s10) aman. Lebah dengan dua kaki dan tubuh bertitik (s11) berbahaya. Karena setengah dari lebah tersebut memiliki sayap tunggal dan sisanya memiliki sayap ganda, jumlah sayap tidak dapat memprediksi kategori stimulus.
Percobaan ini mengikuti desain antar-subjek 2 (skema umpan balik: penuh, kontingen) × 3 (urutan pembelajaran awal: dasar, LT Mencegah, LT Meningkatkan). Partisipan secara acak ditugaskan ke salah satu dari enam kondisi. Mereka diberi peran sebagai peternak lebah dengan tujuan memaksimalkan madu yang dipanen dari lebah (dikuantifikasi sebagai poin). Beberapa lebah aman untuk didekati, menghasilkan madu yang bernilai +1 poin; sementara beberapa lebah berbahaya, menyebabkan kerugian besar sebesar -3 poin jika didekati. Menghindari lebah tidak menghasilkan keuntungan atau kerugian (0 poin).
Selama sesi instruksi, ketiga dimensi fitur bernilai biner diperlihatkan kepada peserta seperti yang digambarkan dalam Gambar 1a . Peserta diberitahu bahwa prediksi sempurna kategori lebah dimungkinkan berdasarkan kombinasi fitur dan bahwa fitur yang terkait dengan setiap jenis tidak akan berubah selama tugas. Untuk memastikan pemahaman peserta terhadap tugas, mereka harus mencapai skor sempurna pada survei pemahaman yang menanyakan: (1) ketiga dimensi fitur yang akan bervariasi; (2) tujuan tugas; dan (3) konsekuensi menghindari lebah, sebelum melanjutkan ke sesi eksperimen.
Peserta kemudian menyelesaikan enam blok dari 16 percobaan pembelajaran diikuti oleh satu blok dari 16 percobaan uji. 2 Dalam setiap percobaan pembelajaran, stimulus lebah muncul di layar bagi peserta untuk membuat keputusan pendekatan/penghindaran tanpa batas waktu, menggunakan tombol di layar (Gbr. 1b ). Jika seorang pembelajar mengklik tombol pendekatan, mereka diberitahu kategori lebah yang sebenarnya dan menerima hasil yang sesuai. Umpan balik kategori korektif juga muncul setelah respons penghindaran dalam kondisi umpan balik penuh, tetapi dihilangkan dalam kondisi umpan balik kontingen. Setelah setiap respons, layar umpan balik ditampilkan selama 2 detik diikuti oleh interval 500 ms di antara percobaan. Percobaan uji identik dengan percobaan pembelajaran, kecuali bahwa tidak ada umpan balik yang diberikan setelah respons.
Urutan 24 percobaan pembelajaran pertama menentukan tiga kondisi urutan pembelajaran awal (Gbr. 2c ). Dalam kondisi LT Promote, urutan stimulus pada 24 percobaan pertama adalah s 00 → s 01 → s 00 → s 01 → s 11 → s 11 sebanyak tiga kali, lalu diikuti oleh s 10 sebanyak enam kali. Dalam kondisi LT Prevent, urutan yang sesuai adalah s 00 → s 01 → s 00 → s 01 → s 10 → s 10 → s 11 → s 11 yang diulang tiga kali. Dengan kata lain, partisipan dalam kondisi LT Promote memiliki kesempatan untuk mengalami hanya satu jenis lebah yang aman secara ambigu (yaitu, s01) sebelum menjumpai lebah yang berbahaya sehingga satu dimensi tampak prediktif terhadap kategori stimulus dalam urutan pembelajaran awal. Sebaliknya, partisipan dalam kondisi LT Prevent memiliki kesempatan untuk mengalami semua jenis lebah yang aman sebelum menjumpai lebah yang berbahaya. Setelah 24 percobaan pertama, delapan stimulus unik muncul sekali untuk delapan percobaan berikutnya dalam urutan acak. Urutan stimulus diacak semu untuk sisa percobaan sehingga setiap stimulus lebah yang unik muncul dua kali di setiap blok. Untuk menilai dampak pengalaman awal pada pembentukan perangkap, kami juga melakukan kondisi dasar di mana urutan penyajian stimulus dalam blok diacak semu oleh subjek di seluruh percobaan.
Peserta memulai tugas dengan perolehan 50 poin. Poin diakumulasikan di seluruh percobaan dan ditampilkan sebagai penghitungan di bagian kanan atas layar dalam percobaan pembelajaran. Dalam percobaan, poin terus diperoleh tetapi penghitungan tidak ditampilkan. Setelah selesai, peserta menerima pembayaran bonus berdasarkan penghitungan akhir mereka.
Percobaan ini diprogram dalam jsPsych (de Leeuw, 2015 ). R (R Core Team, 2023 ) digunakan untuk pemasangan model dan Jamovi (jamovi, 2025 ) untuk analisis statistik.
3 Hasil
3.1 Pembelajaran strategi kategori
Untuk memeriksa efek pengalaman awal pada pembentukan perangkap, kami menilai perubahan dalam prevalensi aturan kategori yang berbeda di enam blok pembelajaran dan satu blok pengujian sebagai fungsi dari urutan pembelajaran awal yang dimanipulasi dan umpan balik. Kami mengidentifikasi aturan kategori peserta yang digunakan di setiap blok berdasarkan pola pendekatan dan keputusan penghindaran mereka (lih. Rich & Gureckis, 2018 ). Secara hipotetis, jika peserta mendasarkan keputusan mereka pada aturan 2D yang optimal (Gbr. 2a ), mereka harus mendekati semua lebah aman s00, s01, dan s10, dan menghindari lebah berbahaya s11. Sebaliknya, jika peserta mengandalkan aturan 1D (Gbr. 2b ), mereka akan tetap mendekati s00 dan menghindari s11, tetapi secara tidak tepat menghindari salah satu jenis lebah yang ambigu (baik s01 atau s10).
Seorang peserta dianggap menggunakan aturan kategori tertentu dalam satu blok jika pola pilihan mereka konsisten dengan prediksi aturan pada setidaknya 15 dari 16 percobaan (Rich & Gureckis, 2018 ). Penggunaan aturan 1D berdasarkan dimensi relevan 1 atau 2 (Gbr. 2b ) digabungkan untuk analisis. Respons terhadap lebah yang terdiri dari fitur relevan yang sama tetapi fitur tidak relevan yang berbeda digabungkan untuk analisis. Jika perilaku pilihan peserta dalam satu blok tidak konsisten dengan aturan 1D atau 2D, mereka dianggap menggunakan aturan yang tidak terklasifikasi. Mengingat minat kami dalam pembentukan perangkap pembelajaran, kami terutama berfokus pada hasil untuk pengguna aturan 1D dan 2D. Kami juga membuat tiga subkelompok pembelajar (pembelajar aturan 1D, pembelajar aturan 2D, pembelajar aturan yang tidak terklasifikasi) berdasarkan jenis aturan yang paling sering mereka gunakan di seluruh blok. Penilaian poin yang terkumpul mengonfirmasi bahwa pembelajar aturan 2D memperoleh poin lebih banyak (dengan umpan balik lengkap: M = 122, SD = 7,54; dengan umpan balik bersyarat: M = 123, SD = 6,85) daripada mereka yang menggunakan 1D (dengan umpan balik lengkap: M = 102, SD = 6,64; dengan umpan balik bersyarat: M = 97,8, SD = 5,30) atau aturan yang tidak terklasifikasi (dengan umpan balik lengkap: M = 84,5, SD = 18; dengan umpan balik bersyarat: M = 84,6, SD = 17,7), F (2, 450) = 478,1, p < .001.
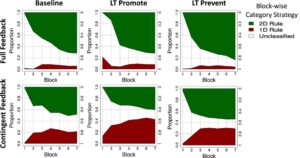
Baris teratas dari Gambar 3 menunjukkan bahwa, ketika umpan balik penuh diberikan, sebagian besar peserta mempelajari aturan 2D yang optimal dalam semua kondisi pengalaman awal. Hanya sedikit ( < 10%) yang terjebak dalam penggunaan aturan 1D. Sebagai perbandingan, prevalensi pengguna aturan 1D meningkat, sedangkan pengguna aturan 2D menurun dalam kondisi umpan balik kontingen (baris terbawah pada Gambar 3 ). Sebaliknya, di bawah umpan balik kontingen, prevalensi pengguna aturan yang berbeda berbeda di seluruh kondisi pengalaman awal. Dibandingkan dengan kondisi dasar, penggunaan aturan 1D dalam uji coba (yaitu, Blok 7) meningkat dalam kondisi LT Promote (lihat Tabel 1 ), bersamaan dengan penurunan penggunaan aturan 2D. Namun, prevalensi pengguna aturan 1D dan 2D di Blok 7 tetap pada tingkat yang sama antara kondisi LT Prevent dan dasar.
| Masukan | Urutan Urutan Awal | Bahasa Indonesia: 2D | Ukuran 1D | Tidak terklasifikasi |
|---|---|---|---|---|
| Penuh | Garis dasar | 72% | 5,3% dari | 22,7% dari total |
| LT Promosikan | 72% | 8% | 20% | |
| LT Mencegah | 83,8% | 3,7% dari | 12,5% | |
| Kontingen | Garis dasar | 48% | 21,3% | 30,7% dari |
| LT Promosikan | 40% | 42,7% | 17,3% | |
| LT Mencegah | 54% | 28,9% | 17,1% dari |
Untuk menguji secara statistik efek manipulasi kelompok kami terhadap perubahan kemungkinan penggunaan aturan kategori yang berbeda (yaitu, 1D, 2D, tidak terklasifikasi) di seluruh blok (seperti yang digambarkan dalam Gambar 3 ), kami melakukan analisis regresi logistik multinomial. Kami menggunakan seleksi mundur berdasarkan uji rasio kemungkinan (Li et al., 2021 ; Matuschek, Kliegl, Vasishth, Baayen, & Bates, 2017 ) untuk menentukan regresi logistik multinomial paling parsimonius yang memprediksi peluang penggunaan aturan yang berbeda berdasarkan kondisi umpan balik, urutan urutan dalam pembelajaran awal, dan blok. Hasil uji omnibus untuk setiap istilah yang termasuk dalam model paling parsimonius (
3 = .202) dirangkum dalam Tabel 2 , yang menguatkan signifikansi efek utama pengalaman awal dan blok, istilah interaksinya, dan interaksi antara umpan balik dan blok pada peluang mempelajari strategi kategori yang berbeda. Koefisien yang diestimasikan dirangkum dalam Materi Tambahan (lihat Tabel S1 ), yang mengonfirmasi bahwa, dibandingkan dengan kondisi dasar, peluang menggunakan aturan 1D lebih tinggi, sementara peluang menggunakan aturan 2D lebih rendah di seluruh blok dalam kondisi LT Promote. Di sisi lain, peluang menggunakan aturan 1D atau 2D tetap sama antara kondisi dasar dan LT Prevent. Hasil ini menunjukkan bahwa pengalaman belajar awal memainkan peran penting dalam pengembangan perangkap pembelajaran 1D.
| Prediktor | χ2 | df | nilai p |
|---|---|---|---|
| Masukan | 1.430 | 2 | .489 |
| Urutan Urutan Awal | 40.180 | 4 | < .001 |
| Memblokir | 217.790 | 12 | < .001 |
| Urutan Awal × Blok | 62.200 | 24 | < .001 |
| Umpan Balik × Blokir | 21.120 | 12 | .049 |
Catatan . Koefisien yang diestimasikan dirangkum dalam Materi Tambahan (Tabel S1 ).
Kami juga menilai perubahan dalam pola pilihan pengguna aturan yang berbeda di seluruh blok (lihat Materi Tambahan untuk detailnya). Hasilnya mengonfirmasi bahwa urutan pembelajaran awal yang dimanipulasi dalam kondisi LT Promote meningkatkan peluang penggunaan aturan 1D tertentu dengan mengandalkan dimensi relevan tunggal yang dimaksudkan untuk menjadi bias (yaitu, dimensi relevan 1, karena s11 muncul sebelum s10 dalam uji coba pembelajaran awal kondisi LT Promote; lihat juga Gambar 2b,c ). Ini menunjukkan bahwa pengalaman awal dapat membentuk bagaimana perangkap pembelajaran terbentuk.
Untuk menguji ketahanan hasil ini, kami melakukan studi replikasi konseptual dari tiga kondisi pengalaman awal dengan umpan balik kontingen, menggunakan serangkaian rangsangan visual yang lebih abstrak (lihat Materi Tambahan) dengan struktur kategori dasar yang sama seperti studi asli kami (Gbr. 1a ). Prosedur eksperimen identik dengan kondisi umpan balik kontingen asli. Peserta menemukan serangkaian fitur baru lebih sulit dipelajari dibandingkan dengan yang digunakan dalam tugas pemanen madu asli kami. Kondisi dasar dalam replikasi konseptual menunjukkan peningkatan penggunaan aturan 1D dan penurunan penggunaan aturan 2D dibandingkan dengan dasar asli. Meskipun demikian, pola kualitatif utama dalam kondisi urutan pembelajaran awal direplikasi (Gbr. 4 ). Manipulasi LT Promote sekali lagi mendorong pembentukan perangkap, sebagaimana dibuktikan oleh peningkatan penggunaan aturan 1D dan penurunan penggunaan aturan 2D dibandingkan dengan dasar. Kondisi LT Prevent sekali lagi gagal meningkatkan penggunaan aturan 2D yang optimal. Namun, tidak seperti studi asli, pengurangan penggunaan aturan 1D diamati dalam kondisi LT Prevent.

Bertentangan dengan ekspektasi, urutan pembelajaran awal dalam kondisi LT Prevent dari studi utama dan replikasi konseptual tidak meningkatkan prevalensi penggunaan aturan 2D. Satu kemungkinan alasan untuk hasil ini adalah bahwa urutan awal yang dimanipulasi dalam kondisi ini mungkin tidak optimal untuk menarik perhatian ke dua dimensi yang relevan untuk kategorisasi. Seperti yang disarankan dalam studi sebelumnya (Lejarraga, Schulte-Mecklenbeck, Pachur, & Hertwig, 2019 ), orang cenderung menggunakan lebih banyak sumber daya perhatian saat menghadapi kerugian daripada keuntungan. Dalam kondisi LT Prevent, item awal dalam urutan pembelajaran awal (yaitu, s 00 → s 01 → s 00 → s 01) selalu menghasilkan imbalan positif untuk respons pendekatan, yang mungkin tidak mendorong penggunaan sumber daya perhatian yang cukup untuk mempelajari aturan kategori yang optimal. Terkait dengan itu, tidak adanya contoh dari kategori kontras (misalnya, lebah berbahaya) pada uji coba awal mungkin telah mempersulit peserta untuk mempelajari fitur-fitur yang membedakan kategori tersebut (lih. Carvalho & Goldstone, 2017 ).
Oleh karena itu, kami menguji coba versi alternatif dari kondisi LT Prevent di mana peserta masih memiliki peluang substansial untuk menemukan semua konjungsi yang aman di awal pembelajaran, namun lebah berbahaya (s11) muncul lebih sering (lihat detail kondisi LT Prevent lanjutan dalam Materi Tambahan). Prevalensi pembelajar aturan 2D yang diamati dalam studi lanjutan ini tetap serupa dengan kondisi dasar, yang menunjukkan bahwa intervensi yang lebih kuat mungkin diperlukan untuk mengarahkan kembali mereka yang awalnya cenderung terperangkap oleh aturan sederhana dalam paradigma pembelajaran kategori multifitur saat ini.
3.2 Hubungan antara perhatian selektif dan pembelajaran kategori
Berdasarkan pekerjaan pemodelan Rich dan Gureckis ( 2018 ), kami menyelidiki bagaimana pengalaman awal berinteraksi dengan distribusi perhatian berdasarkan dimensi dalam pembentukan perangkap pembelajaran. Rich dan Gureckis ( 2018 ) memperluas model pembelajaran kategori berbasis contoh (ALCOVE) milik Kruschke ( 1992 ) yang terkenal untuk memperhitungkan pembelajaran penguatan dari umpan balik bergantung respons dalam kategorisasi multifitur (seperti kondisi umpan balik bergantung dalam studi saat ini). Model ALCOVE-Pembelajaran Penguatan (RL) ini mampu mensimulasikan pengembangan perangkap pembelajaran aturan sederhana dengan memaksakan bobot perhatian yang tidak merata di antara dimensi fitur. Kami membangun pekerjaan pemodelan ini dengan dua cara. Pertama, kami melampaui simulasi dengan menyesuaikan ALCOVE-RL dengan data pembelajaran partisipan. Kedua, kami menggunakan ALCOVE-RL sebagai model pengukuran untuk memperoleh estimasi perhatian selektif berbasis model percobaan demi percobaan untuk pembelajar individu dan memeriksa bagaimana estimasi ini dipengaruhi oleh manipulasi urutan pembelajaran kami.
Seperti banyak model pembelajaran kategori lainnya (misalnya, Galdo, Weichart, Sloutsky, & Turner, 2022 ; Kruschke, 1992 ; Love, Medin, & Gureckis, 2004 ; Nosofsky, 1986 ; Weichart, Galdo, Sloutsky, & Turner, 2022 ), ALCOVE-RL mewujudkan kontribusi masukan stimulus terhadap aktivasi suatu contoh dalam ruang psikologis melalui bobot perhatian dimensional (misalnya, α dalam Persamaan 1 dalam Materi Tambahan). Bobot perhatian yang tidak merata mencerminkan perhatian selektif terhadap dimensi masukan yang berbeda. 4 Untuk memeriksa perubahan bias perhatian dengan rangkaian pembelajaran awal yang dimanipulasi dan umpan balik, kami memperoleh bobot perhatian percobaan demi percobaan menggunakan parameter ALCOVE-RL yang paling sesuai dan mengukur derajat perhatian selektif terhadap dimensi yang relevan dengan mengambil perbedaan absolut dalam bobot perhatian untuk dimensi yang relevan (yaitu, |α 1 − α 2 | yang dinormalisasi; lihat penjelasan terperinci dalam Materi Tambahan). Perbedaan yang lebih besar menunjukkan bias perhatian yang lebih kuat terhadap satu dimensi.
Di bawah ini, kami menyoroti temuan utama dari penyesuaian model ini. Rincian deskripsi model, prosedur penyesuaian model, dan hasil tersedia di Materi Tambahan. Secara kualitatif, model tersebut menangkap pola pilihan khas pembelajar aturan 1D dan 2D (yaitu, pembelajar aturan 2D cenderung mendekati semua lebah aman, sementara pembelajar aturan 1D cenderung tidak mendekati s01 atau s10 dibandingkan dengan s00). Secara kuantitatif, proporsi pilihan yang diprediksi oleh model berkorelasi positif dengan data yang diamati, r (905) = .590, p < .001 (lihat Materi Tambahan untuk pembahasan terperinci tentang evaluasi penyesuaian model). Kami melihat penyesuaian ini cukup untuk menggunakan ALCOVE-RL sebagai model pengukuran untuk penyelidikan interaksi antara pengalaman awal dan distribusi perhatian pada pembentukan perangkap.
Pertanyaan utama kami yang dijawab oleh analisis penyesuaian model adalah bagaimana pengalaman awal memengaruhi perhatian selektif. Gambar 5 memetakan tingkat bias perhatian dalam setiap kondisi dan menunjukkan bahwa bias perhatian terhadap satu dimensi jauh lebih tinggi dalam kondisi LT Promote daripada kondisi dasar atau LT Prevent dengan umpan balik kontingen. Sebaliknya, bias ini tetap pada tingkat yang sama di seluruh kondisi pengalaman awal dengan umpan balik penuh.
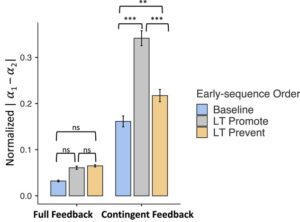
Analisis 2(umpan balik) × 3(pembelajaran awal) dari ukuran bias perhatian mengonfirmasi bahwa bias lebih kuat dalam kondisi umpan balik kontingen daripada dalam kondisi umpan balik penuh, F (1, 3186) = 537,1, p < .001, ω 2 = 0,137. Ada pula efek utama yang signifikan dari urutan pembelajaran awal, F (2, 3186) = 55,4, p < .001, ω 2 = 0,028, dan interaksi antara urutan pembelajaran dan umpan balik, F (2, 3186) = 33,7, p < .001, ω 2 = 0,017. Gambar 5 menunjukkan bahwa interaksi ini terutama didorong oleh bias perhatian yang ditekankan dalam kondisi LT Promote dengan umpan balik kontingen.
4 Diskusi umum
Pekerjaan saat ini meneliti peran pengalaman awal dan interaksinya dengan perhatian selektif dalam pengembangan perangkap pembelajaran kategori aturan sederhana. Hasil kami mengonfirmasi hipotesis Rich dan Gureckis ( 2018 ) bahwa pengalaman kehilangan di awal rangkaian pembelajaran akan mendorong pembentukan perangkap. Ketika satu dimensi fitur tampak prediktif terhadap contoh kategori yang terkait dengan kehilangan atau penghargaan dalam pembelajaran awal (kondisi LT Promote), peserta lebih cenderung fokus pada dimensi itu dan lebih kecil kemungkinannya untuk menemukan aturan kategori optimal yang lebih kompleks. Mereka yang jatuh ke dalam perangkap aturan sederhana menghindari stimulus penghargaan, memperoleh penghasilan yang jauh lebih sedikit selama pembelajaran daripada mereka yang menemukan aturan optimal. Setelah terbentuk, perangkap itu tetap ada meskipun ada peluang lebih lanjut untuk mengeksplorasi stimulus lain. Analisis berbasis model kami mengungkapkan bahwa pengalaman awal memengaruhi perhatian peserta serta perilaku mereka. Pembelajar lebih cenderung membatasi perhatian mereka pada satu dimensi relevan dalam kondisi LT Promote daripada dalam kondisi lain. Hasil ini direplikasi dalam studi lanjutan dengan serangkaian stimulus visual baru.
Penelitian saat ini memperkuat pandangan bahwa perangkap pembelajaran muncul dari siklus eksplorasi, perhatian, dan pembelajaran yang terus berlanjut. Pembelajaran dini mengarah pada keyakinan yang salah tentang fitur-fitur lingkungan yang memprediksi imbalan dan kerugian. Keyakinan yang salah ini membatasi perhatian pada sebagian fitur yang relevan dan mengarah pada penghindaran rangsangan yang memberi imbalan. Dalam lingkungan tempat umpan balik hanya diterima saat suatu item didekati, hanya ada sedikit peluang bagi keyakinan yang salah untuk diperbaiki dan perangkap tersebut terus berlanjut.
Konsisten dengan pandangan ini, dan dengan temuan sebelumnya, perangkap aturan sederhana jarang diamati dalam kondisi umpan balik penuh (Lee et al., 2024 ; Li et al., 2021 ; Rich & Gureckis, 2018 ). Khususnya, bahkan ketika manipulasi urutan pembelajaran awal mendukung pengembangan aturan satu dimensi dalam kondisi LT Promote, partisipan dengan cepat lolos dari perangkap ketika mereka menerima umpan balik korektif setelah setiap respons (lihat plot tengah-atas pada Gambar 3 ). Hal ini menyoroti bahwa diskonfirmasi langsung dari aturan yang terlalu sederhana adalah salah satu cara untuk keluar dari perangkap pembelajaran.
Meskipun manipulasi kami terhadap pembelajaran awal berhasil dalam memperkuat pembentukan perangkap, kami kurang berhasil dalam pencegahan perangkap. Di seluruh eksperimen utama dan dua studi lanjutan, kami hanya mengamati pengurangan perangkap pembelajaran dalam kondisi LT Prevent satu kali. Ini menunjukkan bahwa mungkin lebih sulit untuk memperluas perhatian di seluruh dimensi yang relevan daripada membatasi perhatian pada sebagian dimensi dengan memanipulasi pengalaman awal. Satu kemungkinan penjelasan untuk pola ini adalah bahwa, meskipun pengalaman kehilangan besar tertunda dalam kondisi LT Prevent, beberapa peserta mungkin masih mengalami kehilangan besar pada tahap awal pembelajaran (yaitu, dalam delapan percobaan pertama), dan ini cukup untuk membawa mereka ke dalam perangkap. Pekerjaan sebelumnya oleh Li et al. ( 2021 ) membuktikan dampak kerugian besar dibandingkan dengan keuntungan besar pada pembentukan perangkap pembelajaran. Mereka menemukan bahwa membalikkan jadwal pembayaran sehingga hanya kerugian kecil yang dialami (yaitu, mendekati s00, s01, dan s10 mengakibatkan kerugian kecil sebesar -1 poin, tetapi mendekati s11 mengakibatkan keuntungan besar sebesar +3 poin) secara drastis mengurangi pembentukan perangkap. Berdasarkan hasil ini, penelitian selanjutnya dapat meneliti apakah pengalaman kerugian kecil di awal pembelajaran mengurangi prevalensi perangkap.
Jika dipikir-pikir, hasil yang berbeda untuk kondisi LT Promote dan LT Prevent kita mungkin tidak tampak begitu mengejutkan. Kondisi LT Promote mendorong lebih banyak orang untuk mempelajari aturan kategori sederhana yang memiliki beberapa manfaat bagi pembelajar (misalnya, memungkinkan mereka untuk menghindari kerugian). Namun, tujuan LT Prevent lebih menantang—untuk mendorong orang untuk terus mengeksplorasi stimulus kategori hingga mereka menemukan aturan yang lebih kompleks yang menghindari kerugian dan mengoptimalkan imbalan.
Berdasarkan upaya pemodelan Rich dan Gureckis ( 2018 ), kami menggunakan ALCOVE-RL sebagai model pengukuran untuk menyelidiki interaksi antara pengalaman awal dan distribusi perhatian dalam pembentukan perangkap. Meskipun model tersebut bekerja cukup baik dalam menangkap pola pilihan utama yang diamati, kami mencatat bahwa model tersebut cenderung meremehkan proporsi pilihan pendekatan untuk lebah yang aman dan melebih-lebihkan pilihan pendekatan untuk lebah yang berbahaya (lihat Materi Tambahan). Hal ini kemungkinan karena pembaruan jaringan percobaan demi percobaan dalam ALCOVE-RL mungkin meremehkan kecepatan pelajar mengalihkan perhatian mereka di antara dimensi (misalnya, Rehder & Hoffman, 2005 ).
Selain itu, ALCOVE-RL dibatasi oleh asumsi bahwa contoh-contoh yang dialami dikodekan dan disimpan dengan sempurna dalam memori selama mengerjakan tugas (misalnya, Griffiths & Mitchell, 2008 ), yang mungkin tidak selalu benar dalam kenyataan. Penting bagi penelitian di masa mendatang untuk menyelidiki sejauh mana presisi memori dapat memengaruhi pembentukan perangkap pembelajaran, mungkin dengan menggabungkan upaya pemodelan ALCOVE-RL dengan model kandidat lainnya (misalnya, AARM, Weichart et al., 2022 ). Demikian pula, penelitian di masa mendatang dapat memanfaatkan pelacakan mata (misalnya, Blanco et al., 2023 ; Watson et al., 2024 ) untuk memberikan uji yang lebih langsung terhadap prediksi ALCOVE-RL tentang efek pengalaman awal pada perhatian selektif.
Pekerjaan saat ini difokuskan terutama pada analisis perilaku dan kuantitatif bagi mereka yang mempelajari aturan kategori satu dimensi atau dua dimensi. Namun, hasil penyesuaian model kami juga mengungkap beberapa temuan menarik bagi pembelajar tak terklasifikasi yang perilakunya tidak konsisten dengan salah satu aturan. Kami menyajikan analisis terperinci untuk subkelompok ini dalam Materi Tambahan. Singkatnya, bobot perhatian yang diestimasikan mengindikasikan bahwa distribusi perhatian pada fitur-fitur relevan dari subkelompok ini sebenarnya lebih mirip dengan pengguna aturan dua dimensi daripada pembelajar aturan satu dimensi. Ini menunjukkan bahwa distribusi perhatian yang luas di seluruh fitur stimulus tidak menjamin pembelajaran kategori yang optimal. Selain memperhatikan fitur-fitur relevan, penting untuk mempelajari pemetaan yang benar dari fitur-fitur ini ke hasil kategori. Pemeriksaan parameter pembelajaran contoh/hasil ALCOVE-RL ( l ω ; lihat Materi Tambahan) menunjukkan bahwa pembelajar tak terklasifikasi sering kali kesulitan mempelajari pemetaan ini. Akibatnya, kelompok tak terklasifikasi mengumpulkan penghasilan yang jauh lebih rendah selama fase pembelajaran dibandingkan dengan pengguna aturan 1D dan 2D.
Singkatnya, penelitian terkini menyelidiki dampak pengalaman awal dan interaksinya dengan perhatian selektif pada pembentukan perangkap pembelajaran aturan sederhana. Temuan kami mengonfirmasi peran penting yang dimainkan oleh pengalaman pembelajaran awal dalam membentuk perkembangan perangkap pembelajaran, serta memberikan wawasan bernuansa tentang interaksinya dengan perhatian selektif dalam pembentukan perangkap di lingkungan multifitur. Selain memberikan pemahaman yang lebih mendalam tentang mekanisme kognitif yang mendasari perangkap pembelajaran, hasil kami memiliki implikasi untuk pembelajaran di luar laboratorium. Hasil tersebut memperkuat bahwa, di bawah kendala lingkungan umum berupa umpan balik kontingen, perangkap adalah hal yang umum dan sulit dicegah. Meskipun demikian, hasil kami menunjukkan bagaimana lingkungan pelatihan harus disusun jika kita ingin menghindari potensiasi perangkap.

